


AI Foundations Part 1: Transformers, Pre-Training and Fine-Tuning, and Scaling
I'm getting up to speed on AI, and I thought I would take you all along.
I’m trying to become a bit more knowledgeable about AI. I did a deep dive in 2018, but I have been a bit stale since I first learned about neural networks. I assumed that LLMs and the recent advancements were a linear scaling of that.
There’s a lot more to it than I thought. I’m trying to fix that, and I thought I’d share what I learned in my newsletter. If you want to join me on this learning journey and series of posts, please join the over 23,000 free subscribers of Fabricated Knowledge so you don’t miss the next post in this series!
There’s been a few breakthroughs that have made ChatGPT possible. I want to summarize and explain what made some of the breakthroughs in generative AI possible at a fundamental level. I want to start with the transformer, pre-training models, and then a discussion of scaling models. This will inevitably end up as a multi-part series.
To start, I asked ChatGPT about some significant papers for learning about Large Language Models (LLMs), and it provided some suggestions. I’ll be using ChatGPT heavily throughout. I started with this helpful survey, and after reading it, I have a simplified path of how we got to ChatGPT explained through papers.
These are the foundational papers:
Attention is All You Need (Transformer Model) December 2017
Improving Language Understanding by Generative Pre-Training (GPT-1) June 2018
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (BERT) October 2018
Large Language Models are Unsupervised Multitask Learners (GPT-2) February 2019
Scaling Laws for Neural Language Models (OpenAI Scaling Paper) January 2020
Language Models are Few-Shot Learners (GPT-3) May 2020
Training Compute Optimal Large Models (Chinchilla) March 2022
I originally wanted this to be a taxonomy of all papers, but I decided to cut this into parts. This post will cover transformers, pre-training and fine-tuning, and scaling models larger. The next post will discuss the Mixture of Experts, Prompting, and Sparsification.
Let’s begin with transformers, the foundational building block of large neural network models today. I’ll start with the famous “Attention is All You Need” paper. This will be the most technical part of the piece, and from there will get easier to understand. But understanding Transformers is crucial because that’s the foundation of all LLMs.
Attention is All You Need (Transformers)
“Attention is All You Need” is a seminal paper in the machine learning space. Introducing the Transformer model was important in pushing AI forward from the previous architecture of RNN (Recurrent Neural Networks) and CNNs (Convolutional neural networks) in sequence-to-sequence tasks. Sequence-to-sequence tasks are the most common NLP (natural language processing) tasks and refer to when a neural network takes one sequence and outputs another response sequence.
The Transformer model was an evolution of the previous techniques. Importantly that importantly scaled to parallel computing more naturally than the previous techniques. The key mechanism here is the multi-head attention layer, which is why the paper title is “Attention is all you Need.”
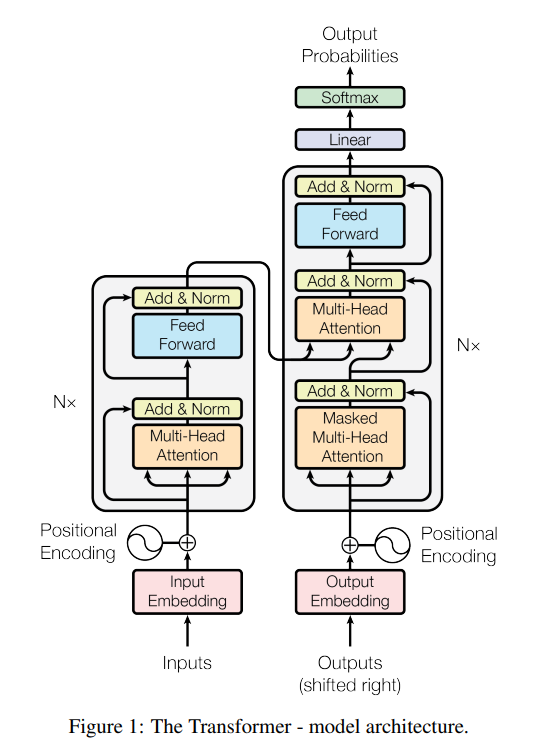
I’m going to try to explain each step in the above figure. I apologize if it’s technical, I’ll have a non-technical summary at the end. You can skip below the line for the simplistic comparison against RNNs and summary.
The input layer is a sequence of word embeddings, and each word embedding is called a token. For each token, three linear projections are computed, the Query (Q), Key (K), and Value (V) vectors. These are created using weight matrices that are learned during the training process. There are often billions of tokens in each model.
The attention score is calculated by taking a specific token's dot product of the Q vector (Query) with the K vectors of all other tokens in the sequence. This creates a score representing the importance of the other words in the sequence. The attention score holds each weight’s importance in the model.
The attention scores are then scaled down by dividing them by the square root of the dimension of the Q and K vectors to create smaller dot products for the softmax function. The softmax function takes the attention scores and converts them into probabilities of the scores but ensures the scores sum to 1. The softmax output is multiplied by the V vectors, creating a weighted representation of each token’s value. The final weighted vectors are summed to produce the self-attention layer for each token, and that output is passed to the next layer of the transformer architecture. The training weight is important and the solved “solution” of the relationship between the token and the output.
Importantly the multi-head attention mechanism performs this multiple times with different weight matrices, allowing the model to focus on different aspects of the input. The self-attention mechanism allows the transformer to dynamically weigh the importance of each token in the input sequence when making predictions or generating text, better capturing long-range dependencies in the data. Multi-head attention creates a level of parallelism that didn’t exist in prior neural networks.
Each Transformer cell is a layer in the model, and large models have many layers. A “parameter” is each of the weights in the model. For example, GPT-3 has 96 layers and ~175 billion parameters.
Let’s compare this to RNNs, the previous state-of-the-art model type. RNNs processed sequences sequentially, one token at a time, instead of all at once like a transformer. Self-attention means the entire length of tokens is considered, given the weighting of the vectors.
Moreover, because they are not sequential, they can be highly parallelized, meaning the entire model can be trained simultaneously. Imagine working on a car. Instead of waiting for the chassis to be built, every aspect of the car can be worked on and tuned simultaneously. This highly speeds up the super complex process of training models.
There are drawbacks, as RNNs require less computation and memory than a Transformer of the same size. However, Transformers can scale up much better and improve with scaling, an important defining feature of LLMs.
There’s also something uniquely elegant about the Transformer. It is a single unit that is scaled up and creates emergent complexity as it has more and more units. For some reason, this rhymes more with neurons than we’ve done in the past. Simple prime structures scaled to infinity seem to be the correct way to proceed, and the Transformer intuitively follows this pattern.
One of the best explainers of Transformers and one of the best youtube videos.
Okay, wow, I’m proud of you for getting this far. I promise the rest of the paper summaries will be more simple.
BERT and GPT-1: Pre-Training and Fine-Tuning
From here, I want to talk about BERT and GPT-1, which came out around the same time. I’ll discuss GPT-1 before BERT, but both have a similar breakthrough. The difference is that GPT is left to right for language models, while BERT is bi-directional, meaning right to the left, and left to right understanding. GPT-1 first.
GPT-1
OpenAI introduced GPT-1 in their paper Improving Language Understanding by Generative Pre-Training. GPT-1 used the Transformer architecture (explained above) to create a highly parallel structure performed at state-of-the-art levels.
Importantly there were two stages of training GPT-1, unsupervised pre-training and then supervised fine-tuning. The unsupervised pre-training used a large corpus of text to learn the general language and then was fine-tuned on labeled datasets for specific tasks.
Think of pre-training as general education from elementary to high school. Fine-tuning is the much shorter process of college to specialize in a model for a task.
The general education a model gets (pre-training) does seem to have some transfer learning and usefulness for when it’s time to specialize the model during the fine-tuning process. GPT and BERT showed the advantages of the pre-training / fine-tuning process and the Transformer architecture’s generalizable power.
BERT
The BERT paper, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, showed similar improvement in pre-training and fine-tuning to GPT but with a bi-directional pattern. This is an important difference between GPT and BERT, which is right to left versus bi-directional.
BERT was pre-trained with two unsupervised tasks, Masked LM and Next Sentence Prediction. BERT was then fine-tuned and could perform generalized tasks at state-of-the-art levels. In the paper, they also mention the benefits of scaling said, models.
I wanted to include BERT next to GPT because there is an important schism here: bidirectional versus left-to-right models. The Transformer model hierarchy has a slight split here, and I wanted to note where it started. For example, T5 is a bidirectional model.
LLMs are becoming generalizable.
The important takeaway is that model started to become generalizable through pre-training and then fine-tuning. In the past, models were trained for a specific task at hand, and the pre-train / fine-tune paradigm was important to push LLMs to become state of the art at multiple tasks, not just a single task at a time. This is a big deal. Now let’s continue to GPT-2/3.
GPT-2/3 and Scaling Language Models
GPT-2 saw some interesting changes in the Large Language Model world. The paper, Large Language Models are Unsupervised Multitask Learners, pointed out some key features of LLMs today.
First, GPT-2 was a meaningful scaleup from GPT-1, consisting of 1.5 billion parameters compared to 117 million. Additionally, GPT-2 was trained on a larger dataset called WebText, which contained a much larger dataset than what trained GPT-1.

What was notable about GPT-2 is something called zero-shot learning, the breakthrough of GPT-2 being able to perform well on NLP tasks without any task-specific fine-tuning, aka zero-shot. This is an improvement towards a generalizable model for all language-related tasks. In the primary education and college education analogy, the high schoolers got much smarter when they scaled the model larger.
I think this is where the magic of LLMs begins. Scaling GPT-2 larger created many emergent effects that people didn’t expect, and the first was zero-shot learning. Researchers assumed some fine-tuning would be needed, but as the Transformer based models scaled, that wasn’t the case.
GPT-2 out of the box was much better at long-range context, reading comprehension, and summarization without fine-tuning. GPT-2 started to show that large enough LLMs would improve the model out of the box, and eventual fine-tuning would make it even better. This created a roadmap for improvement.
But the significant improvements in pre-trained zero-shot learning were an eye opener and a clue that GPT-2 was on to something. So let’s discuss scaling laws because after GPT-2 came Scaling Laws for Neural Language Models, which proved some of the relationships found in BERT and GPT-1 and 2.
Bigger is Better in LLMs
The key conclusion is that performance increases in Transformer models as size, dataset size, and compute increase. And it’s in a log-linear model of improvement.
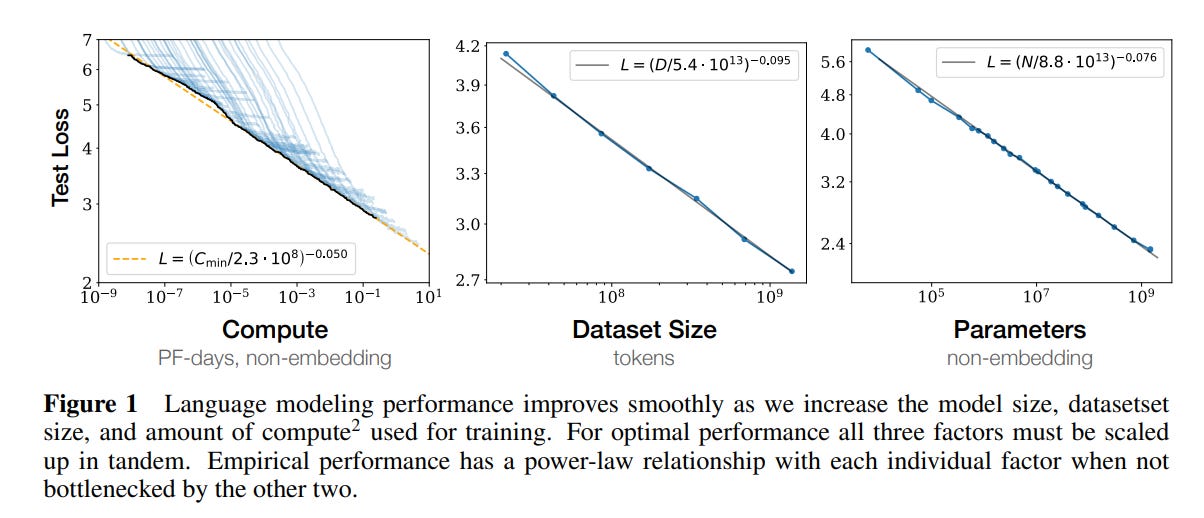
OpenAI cleverly showed that if you constrain each factor, you can tease out a relationship. This implied significant benefits from even larger models. All three factors matter, compute, dataset size, and parameters.

Larger models train faster - meaning the bigger the size, the quicker it converges. This is potential because of the lottery ticket effect and the random parameters that help a model converge.

There’s also a bit of an optimal model size, given the training data size. Training a model that is too large for the data creates overfitting while training a model that’s too small might not lead to the best performance.

What’s more, generalization improves as models get bigger. Meaning that larger models are better at generalizing to unseen data, making them even more robust.
There also doesn’t seem to be an end in the near term, which reminds me of the infamous Moore’s Law. As compute, model size, and data go up; performance goes up until that relationship breaks. We don’t know when it will, and thus we should make bigger models.

These were all huge findings and pushed the field to create bigger, more compute-hungry datasets and bigger parameters for LLMs. But as we will see with Chinchilla, there’s more nuance than you’d think. It’s not right to take this linear lesson to infinity; these scaling laws might be incorrect. But first, we will discuss GPT-3.
GPT-3: Language Models are Few-Shot Learners

GPT-3 took the conclusions from scaling laws to their logical conclusion. GPT-3 is 116x larger in parameter size and has started showing new and interesting things from larger models.
Namely, as the title suggests, LLMs are Few-Shot learners. This means that GPT-3 can generalize and adapt to a wide range of NLP tasks given only a few examples during the fine-tuning phase. The size and power of the pre-trained model started to show meaningful generalization.

Important to this few-shot training paradigm was the use of in-context information. Users can adapt the model’s deep and broad knowledge to different tasks by providing just a little context. This meaningfully improves the model’s performance. This is the beginning of prompting, which gives context in the question to get better performance.
GPT-3 was task-agnostic, and its architecture needed little fine-tuning to be great at specific tasks. Presumably, further fine-tuning can lead to even better models with this base GPT-3 at the core.
This is a big deal. GPT-3 was better than state-of-the-art fine-tuned models, given only a few-shot fine-tuning. This shows that GPT-3 is improving with size and can be generalized into adaptable and broadly applicable language systems. But before we go, I want to talk about Chinchilla.
Chinchilla and Compute-Optimal Large Language Models
Scaling laws and GPT 1 to 4 have shown that larger models are better, but there’s more nuance than originally thought. There’s a size relationship, but there’s much more to the story than what first meets the eye. The Chinchilla paper talks about this.
Scaling Laws showed a power law with larger models, so researchers have been making larger models expecting improvements. Chinchilla claims that large models should be trained with more training tokens than recommended by Scaling Laws, which said that a 10x computational budget should increase the model 5.5x and training tokens 1.8x. Rather Compute-Optimal Large Models should scale model size and training tokens in equal proportions.
Chinchilla is a smaller model trained with a smaller model (parameters) but more training tokens and outperforms much bigger models. Chinchilla is better than Gopher, GPT-3, and Megatron despite a smaller size. The relationship is shown below, and, importantly, it redefines the optimal model size and training tokens given a computing budget.

Scaling laws exist, but we are still in the early days of figuring out the optimal configuration. Chinchilla described a new relationship of scaling laws. The model size is not the only predictor of performance, and data quality, token size, and even context windows will help scale models further. The closer we look, the more we must figure out how to scale these LLMs.
Data, size, and computing are all part of it, and Chinchilla asks the scaling law question again with a different focus on training tokens. It’s not clear that the bulky models are the best way forward, but rather just the first attempt at the final configuration of LLMs. There isn’t a right answer to scale these models, and the devil is in the details. Researchers today are figuring out how to scale up these models, and training tokens is just an example of how to do it better than previously discussed scaling laws.
Conclusion and Takeaways
I discussed foundational papers and processes that got us to where we are today.
The Transformer model is the big revolution that made today's LLMs possible. The Transformer created a highly parallel and scalable architecture that improved with scale.
Using new Transformer based models, we applied pre-training and fine-tuning to improve the model’s performance with GPT-1 and BERT. This pre-training and fine-tuning structure is seen in most of the state-of-the-art models today, with ChatGPT as a fine-tuned model for chatbots from the core GPT model as an example.
GPT-2 and GPT-3 showed that the models started to have emergent improvements, such as better zero-shot learning in GPT-32 and few-shot learning leading to more generalizable models in GPT-3.
Lastly, scaling laws and compute-optimal models showed that bigger models with more data and computing are better. Chinchilla focused on training tokens instead of just raw size and showed that there’s a better efficient frontier of scaling these models.
That brings us to today, with GPT-4 as a successor to the GPT-3 model. These foundational texts help you understand how models scale and fine-tune tasks and how they will continue to improve.
This is not the end of the story, as many more subtle innovations are happening, and I want to further discuss models from Google, Meta, and Microsoft. I want to talk about sparsification, a Mixture of experts, Gshard, and other things happening. OpenAI is one of the leaders in the space, but as I have read and learned more, the race is still on. It’s not even close to the end, which is exciting. I hope to write more about this space soon.
Thanks for reading today! If you enjoyed this, please share! That helps me. What’s more, if you want to subscribe, you’ll be sure to see the next free post about AI. It’s increasingly important to understand the killer application of semiconductors, AI.
I love feedback if you have any questions! I understand if this is a technical topic, and I would love to hear the topics you want to understand. I’m also interested in learning about Stable Diffusion at some point here.