
ChatGPT o1 (Strawberry) and Memory
This is going to be a two part piece. I'm going to do a long bit on memory, and a brief bit on strawberry.
ChatGPT o1 and Strawberry - Algorithmic and Inference
Strawberry was a breakthrough. Some people ask, “What’s the big deal?” but feasibly, there is a new scaling law working in tandem with training, and that’s the Chain of Thought / Inference.
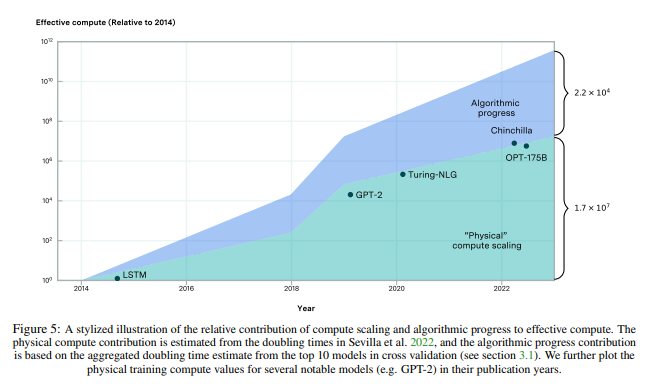
The chart below is a bit confusing, but the conclusion is the longer the model “thinks,” the better the answer. The new model has another log-linear scaling law. It pretty much computes, and the Bitter Lesson wins again.

It’s been a while since I’ve seen such a clear new demand vector. I last wrote about “new” demand vectors from AI during the scaling law paper 2020. This was primarily focused on training.

Now, we have a new potential scaling law that works in tandem with training. Below is a simplified rendition of what computing will look like post-Strawberry. Given that this works without larger models, welcome to a whole new layer of computing demand, and expect it to swell to training-like proportions.

Now, what does that mean for semiconductors? I can explain it to you; a crap ton more computing, and this time, it’s from inference, not just training. Investors are again getting excited about AMD on this, but I still prefer Nvidia or the internal hyperscaler projects over time.
If a product can do inference and training, you can buy both for whatever future needs you can’t anticipate. That’s likely Nvidia GPUs. Yes, this will be a shot in the arm for inference startups and AMD, and if Microsoft gives AMD a custom project, maybe they will continue to have some relevance. However, incumbents are still more likely to retain most of the market share.
The reality is that this is a much-needed next leg of demand. Algorithmic improvement has already been a large deflator on the demand for scaling larger and larger models, and I expect this to continue.
But I think the reality is that this new inference chain of thought “law” will drive more demand than we previously thought. Companies like Groq, for example, just got mana from heaven, and despite my continued skepticism there, it’s a new day for everyone focused on inference. Check out this post from Shelly Palmer about costs:
o1 models handle longer context windows, enabling more comprehensive text understanding and generation. This capability allows for processing larger documents, making them valuable for extensive data analysis and document summarization. However, these enhancements come at a cost. The new models require significantly more computational resources, with operational costs estimated up to 10 times that of GPT-4. One company we work with is spending about $60,000 per month on GPT-4. To do the tasks with o1 would cost approximately $3,000 per hour – which is completely out of the question considering that, for all of their capabilities, o1 models operate at slower inference speeds, presenting a serious trade-off between improved reasoning and processing time.
Strawberry is a big deal. It’s a better outcome at a much smaller model size, fueled by vast amounts of inference. I think it’s also a perfect counterfactual to the concern that model sizes have been getting smaller and more optimized. The smaller the models get now, the more inference compute will be thrown at questions in a chain-of-thought way to get better outputs. And that will happen even as we get to bigger and bigger models.
AI Models improve on themselves in a way that shows massive promise. If Reinforcement Learning happens without humans and costs a lot of inference tokens, we are off to the races yet again. Strawberry is a game-changer, and “The Bitter Lesson” wins yet again.
