


Jensen's World: Compressing Reality
AI factories, digital twins, and why Nvidia is winning the AI race
Correction: I sent out an email with a duplicated portion. This is edited and resent.
Hello from San Jose! I was in person to listen to Jensen’s keynote speech, which was delivered on March 18th. It would be best if you watched the whole thing. It would be helpful if you watched the keynote before this post.
Anyway, I want to articulate one of AI's big whys. I’ll discuss product announcements and then post thoughts on the competitive positioning behind the paywall.
The Future is Simulated: Nvidia's Vision for an AI-Powered World
"It is so much cheaper to do simulations than real experiments, so much more flexible in testing...we can even do things which cannot be done in any lab… So it’s inevitable this trend will continue for some time." - Richard Hamming, The Art of Doing Science and Engineering.
Richard Hamming said this to the President of Bell Labs in the 1950s. And I think this insight rings more accurate than ever. Simulations of reality are much more flexible and cheaper than observing and interacting with reality.
I will assert that LLMs and “AI” are effectively the logical conclusion of this trend. A large language model is trained on the largest amount of data possible, often the entire crawlable Internet, all the books ever written, and so much more.
The model is trained on this dataset to learn the relationships and patterns. The LLM stores the meaning and relationships as a super-summary of all information, and then we can retrieve all of the information from this compression.
Put differently, it is a very efficient summary or simulation of all language and written information. Now that we have a cheaper language simulation, let’s apply Richard Hamming’s core insight: it’s more affordable and easier to simulate or generate this reality on a computer than reality itself.
The Power of Compression: LLMs and the Simulation Revolution
LLMs and AI are the extremes of compression, and while they are the best examples we have today, AI has the potential to help everything eventually achieve this level of compression. We will gather and find as much information and data as possible, train a sufficiently large model to understand the relationships between this data, and then, instead of utilizing reality (learning a new language, creating a website), we will use our compression of the information to generate it instead.
Following the computing trend, using a simulation is cheaper, faster, and more flexible than reality.
Now, for the sake of example, I want you to imagine that we can broaden the scope of this model beyond language. The transformer model has now been used for image and speech recognition, and eventually, we will use AI to compress reality and effectively simulate reality. What if we could apply this to video? That’s effectively OpenAI’s Sora.

Or, if we knew the entire human genome and how proteins folded, we could accurately simulate genomic or drug discovery products. And that’s what Nvidia is trying to model with Nvidia Healthcare.

And I mean, why stop there? Nvidia wants to create Earth 2, a digital twin of Earth, for better weather predictions. This is the logical end of computing compression because it’s cheaper to simulate reality than to experiment in it.
The reality is that the transformer model's generalizability opened up the magic of simulation to anything with enough data and enough compute. While extremely expensive upfront, once the model is made, it will be cheaper than reality. That is the future that Jensen is trying to explain. We can learn anything and understand anything if we have enough data. This is what Jensen means by an “AI factory.”
Once we create the model and simulation of reality, and it is as effective at, say, image generation or video production as we are, it will make sense to generate that model instead of interacting with expensive reality. That’s the entire keynote, just permutations or combinations of this profound truth over and over.
Jensen repeatedly explains the concept of a Generative AI Factory as exploiting the fact that it’s cheaper to simulate reality than to interact with it. Once you understand that, one of the “whys” about pursuing AI with such a scale makes much more sense.
Generating Reality from What We Know
Instead of forecasting weather based on observations of reality, it makes more sense to simulate reality based on models and past observations for more accurate weather predictions. This model doesn’t have to exist in computers; we can accurately change it by incorporating data or feedback from the natural world and then simulating the outcome in a computer.

Or it’s much easier to just simply generate a video of a video of a car commercial instead of shooting one instead. And while it is a non-trivial amount of computing, it is much more efficient than driving out to the desert to shoot a car commercial. It’s a more efficient, cheaper, and often better reality simulation. In the example of a car commercial, you could reshoot the commercial in any color, setting, weather, or environment needed. With better models, it could be imperceivable from reality while vastly cheaper and faster than trying to interact with reality.
Richard Hamming's exact prediction is accurate but outside the narrow scope of experiments. We are not creating experiments; we are simulating reality. It’s a function of generating our model of reality repeatedly and giving us the information as if it happened.
This is what Jensen means by AI Factories creating information as an output. The factory is an Nvidia GPU pod, and the output is an efficient compression of reality.
While it is extremely expensive to create, train, and infer these models, once the compression is done, they will be much cheaper, more flexible, and often give us better data than we could observe from reality itself.
These foundational models are expensive, but once we make them, we will figure out a way to amortize their cost later. This is similar to every single game-changing technological shift.
You can make photo-realistic videos of impossible things that would take hundreds of hours and thousands of dollars. You could create drugs by synthesizing the information we already know about biology. You could make new materials based on our understanding of the world's physics.
This cascading model of the physical universe is what Nvidia calls the Omniverse. Honestly, I think the Metaverse's dream is a digital twin of reality. And looking at it as a much cheaper rendition of our physical world is the correct trend to notice.
We might not live in a simulation, but we are trying to create one for our control. It’s more malleable than reality itself, and instead of having to measure and cut once, we can measure as many times as we want and cut once.
I mean, what are we humans but information-processing and prediction machines? The inside of our brain is a dark and largely stimulus-free space, but it creates a model of our understanding of the world based on the input our senses feed it. We are now pursuing this model building at a larger and more digital scale. We are finally creating the digital twin to rival our first analog models of the world around us: our brain.
And what’s interesting is that I think Nvidia might win it all.
Nvidia Controls the Simulation
It’s not surprising that a company that has been simulating reality for a long time by creating the best video game graphics will be the one that simulates models of our physical reality and language.

When we first started to recreate our world with computers, we did so in pixels and graphic shaders. Somewhere along the way, Jensen and Nvidia realized that there was one level larger the abstraction could go. In today’s keynote, Jensen said AlexNet told him an important leap could be made.
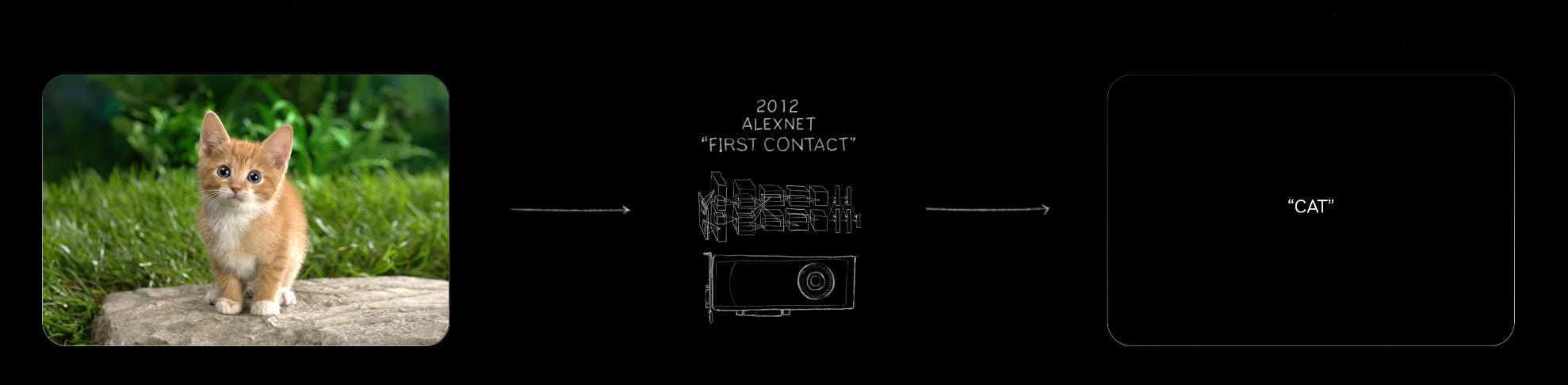
While I think Alexnet truly was the first contact, Transformers was the first glimpse of what was possible. It was a much bigger plan than the original graphics dream, but it was, in some sense, what Nvidia had already been doing: simulating reality using matrix multiplication.
Since then, Nvidia has slowly sketched the path to get there. I think it holds; Jensen put up this incredible graphic during the keynote. Data outpaced CPUs, CUDA, and parallel computing was the first way around this wall. From there, every decision has been an attempt to scale out that computing dream.

Jensen and Nvidia had a front-row seat of the entire story. Slowly but surely, by seeing CUDA research and the problems to be solved, Jensen took steps to make a much bigger GPU to simulate a much bigger reality and made the system do it.
And that’s the Nvidia we come to today. The company had multiple impressive product launches: the B100, the GB200, and the NVSwitch. Additionally, I must mention that Nvidia isn’t much of a GPU company these days but rather a solutions company. Today's DGX pod is not a rack but a whole system, and that’s a good thing.
Product Launches
Let’s first start with the company's legacy, which is GPUs.
Blackwell GPU (B100)

The Blackwell GPU will be compatible with existing H100s, but most customers will likely only install it in greenfield additions. The GPU has 8 TB/s of memory bandwidth and 8 stacks of 8-hi HBM. It should be air-cooled; later, higher memory SKUs will likely be water-cooled.

But that’s not the “big” GPU that Nvidia chooses to highlight. The keynote is about the GB200, a vast improvement on the GH200, as it doubles the GPU-to-CPU ratio.
GB200
As the image below shows, the GB200 is a collection of two Blackwells to one Grace CPU, which lowers the CPU cost and serves as a memory controller for the GPUs.

One GB200 can scale out an additional 480GB of LPDDR5 DRAM, adding another layer of slower cache memory for huge models. While the scaling of HBM is much more desirable, this should make sense, especially for inference nodes.

Now, they add two of these compute nodes to get 4 Blackwell GPUs in a blade and combine multiple blades into a system. Let’s discuss some of Nvidia's networking aspects before we discuss the DGX pod.

NVSwitch and Infiniband
While Ethernet is allegedly the future of networking, Infiniband carried the day with 4 800G NICs out of a blade. These allow for chip-to-chip coherency and networking.

A Bluefield-3 DPU, the likely source of the intelligent inference routing and RAS, also augments this. This in-fabric computing allows for important system-level optimization choices that offer much better than competitor performance.

Last but not least, this is all connected with the NVLINK Switch, which comes together with an impressive system-level optimization—the NVL72.

This is where the magic comes together: The system.
DGX NVL72
This 72-port 1.8TB/s switch system connects each GPU to the others in a cache-coherent way. The aggregate bandwidth is larger than the Internet, at 130TB/s all-to-all.

Now, the real magic seems to be the interconnect, which is highly optimized for Nvidia. As mentioned in the keynote, it's made out of direct copper links because of the high-quality SerDes, and it seems to plug into a proprietary form factor that Nvidia is standardizing.

Bringing it all together, each NV72L will have 72 GPUs and be the cheapest yet fastest networking stack possible. This is a significant moat compared to competitors, who either cannot offer this speed or would have to do so at a considerable transceiver tax.

The entire rack is over an exaflop of AI performance, and the software views it as one giant GPU. This is a miracle of networking and one of the best examples of scale-out we’ve ever seen. The networking steals the show, and the silicon is essential but just a component in the system that Nvidia is offering.

Now, Nvidia can add an Infiniband Switch at the top of the rack and scale the racks together to form a larger node.

The node has 14.4 teraFLOPs of in-network computing and is liquid-cooled at the GPU and switch level. This is a highly tight system solution and integration. What’s more impressive is that this is supposed to come at a relatively modest ASP lift compared to the last generation, as Nvidia looks to be capitalizing its value from the entire system instead of just the silicon of the Blackwell GPU.

I think it’s best to compare the spec sheets. While we know that FP4 is only supported by Nvidia, a like-to-like comparison of the Blackwell GPU to Hopper shows a 2.5x improvement in FP8. That’s a silicon-to-silicon comparison. I understand that FP4 improves it again, but I’m looking at hardware improvements.

Now, the real magic is coming from the scaleout of the GPUs together in a GB200 NVL72 system, which offers a 20x+ improvement over previous racks and a 45x improvement in inference. There seems to be some secret in the network improvement as well.

The real magic shows an extremely impressive per-watt improvement at system-level performance. Training GPT-MoE-1.8T would take 4MW, or 1/4th the power that it would for Hopper. That is a significant TCO improvement; it takes fewer GPUs with less energy.

I want to spend a brief moment to mention some improvements that are coming from the network and are differentiating from Nvidia. First, use the RAS engine, then Inference Optimization.
RAS Engine
Jensen mentioned this interesting anecdote during the keynote.
The likelihood for a supercomputer to run for weeks on end is approximately zero. There are so many components running at the same time the probability of them all working at the same time is extremely low.
And this is where the RAS engine comes in. I read this interesting piece last week about variability in nodes for supercomputers.
Overall, every single cluster we tried feels like they have their own vibe, struggles and failure modes. It was also almost as though every single cluster needed their own hot-fixes for their own set of issues - some more tolerable than others. That said, we’ve learned that fail safes are important, and finding fast hot fixes for any clusters could be key.
Remember, given the time it takes to train GPT4+, there are inevitably failures at the data center level. Nvidia is creating a series of hardware-level monitoring to prevent cluster failure. Nvidia is trying to enable scale-out by improving reliability.
Next, inference optimization.
Inference Optimization
I found this to be one of the most exciting segments of the entire talk. It was a bit complicated to grasp, but there is an efficient frontier of multidimensional optimization that is hard to quantify on an X-Y graph. Each point in blue is an output of that multidimensional problem, and the line in green is the efficient frontier.
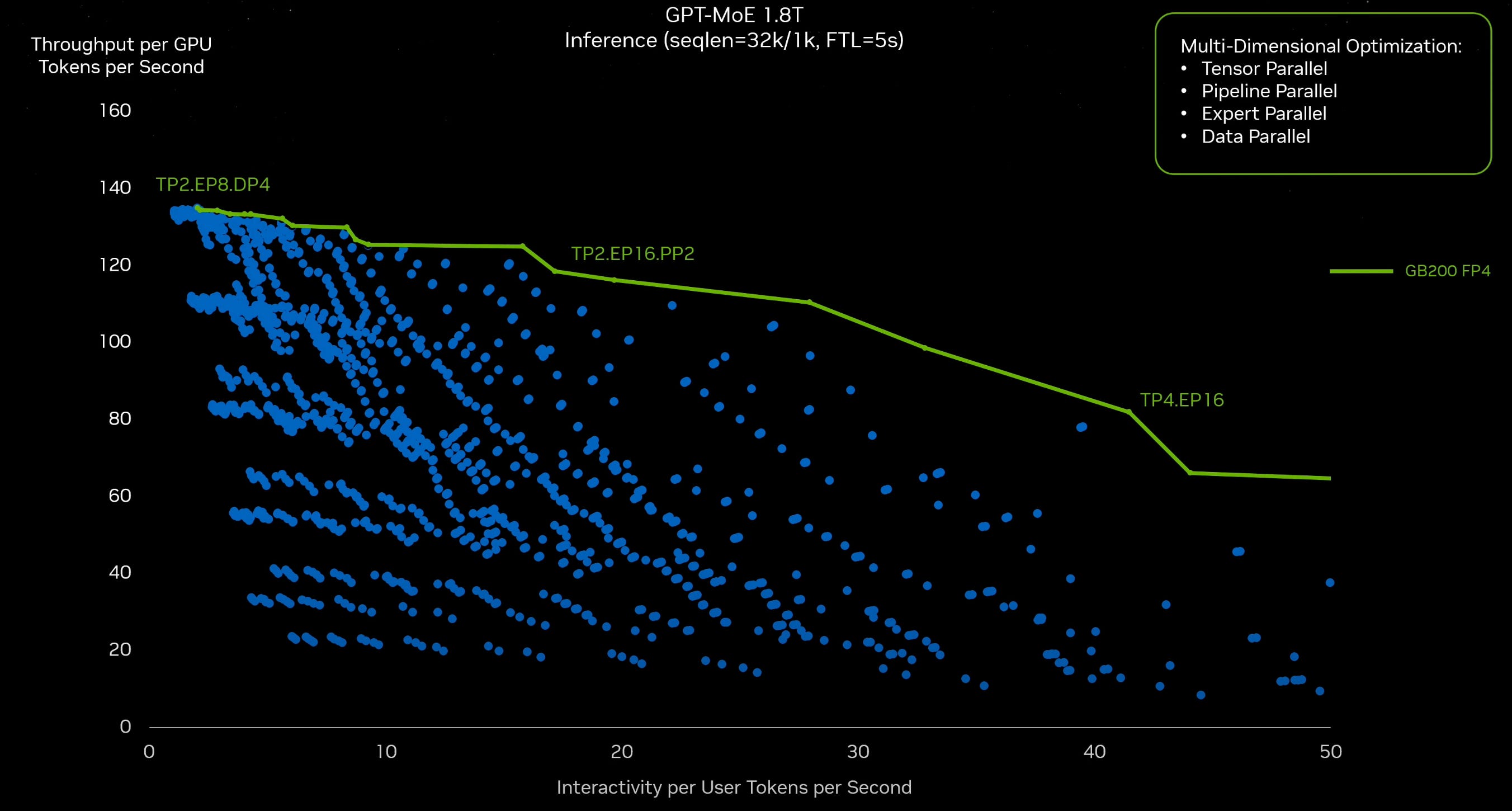
There are various configurations of how data can be accessed in a large model. Think of the compression of data across the entire network and how the GPUs access data. Experts, pipelines, or tensors can all create different throughput options to infer that data from the vast model network.

The speedup is tremendous and implied to be because of the Bluefield DPU. On a silicon-to-silicon basis, the purple line would be comparable to the blue line, and thus, Nvidia is showing you system-level improvements over the network.
The belief that more HBM will be able to be the only scaling factor for inference speed seems completely wrong. Nvidia is flexing its networking muscle to show how it is scaling beyond silicon.
This optimization happens for every type of model. This is a perfect example of system-level optimization that can be used for general model inference improvements. It points to system sophistication that is not likely to be matched by competitors anytime soon.
For example, if AMD were to build an MI-400 with more HBM, it would no longer offer faster or better TCO inference because networking and DPU offer an inference speedup above silicon improvements.
OVX / AGX / GROOT
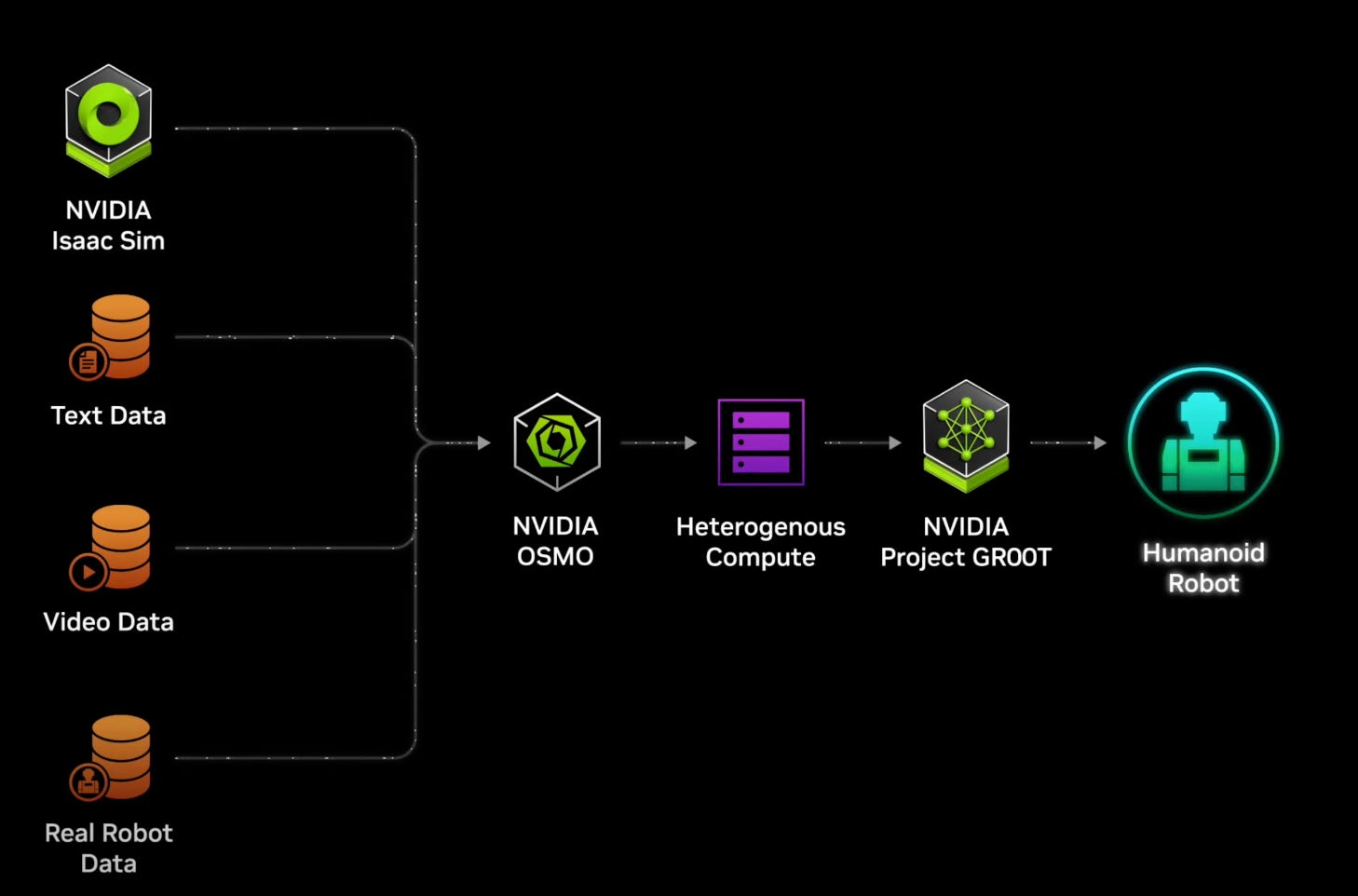
One of the more exciting demos that felt less mature was the OVX and AVX demos. Additionally, I’ll consider GROOT within this embedded context. I think of this entire part of the talk as an extension of the Omniverse vision but in a hub-and-spoke fashion.
The DGX part of the platform trains and creates the models, while OVX simulates them. Lastly, AGX integrates feedback into that simulation so that the system can better interact with reality. The OVX is L40-focused and more of an inferencing machine than a training machine.
When DGX finishes creating a world model, the OVX and AGX are the hub and spoke that will let the natural world and the virtual model interact.

Now enter GROOT. This seems like a new library of likely transformer-based models that can lead to faster humanoid robot creation and training. It remains to be seen how much better these will be than the current solutions. Given recent advances in LLMs, I am very hopeful this can accelerate robotics meaningfully.
NIMs or AI Nvidia Microservice
NIMs are an example of software distribution on their hardware installed base. NIMs is not going to revolutionize AI, but they could revolutionize how we deploy it. NIMs are an example of their continued software and hardware integration, and the packaged deployable “droplets” of software deployed on GPUs are a compelling example of how Nvidia distributes software.

You have to own an Nvidia GPU if you want to participate, and given all the support Nvidia offers, that seems like a bargain.
Now, let’s talk about the specific competitive thoughts that I thought were extremely interesting.
