
NVLink/Switch and Platform Wars, Micron and Datacenter
Nvidia's new Grace and Hopper chips is beginning to open the datacenter, may the best silicon win.
I don’t think I have a particularly great overview of the Grace and Hopper chips that Nvidia announced recently at their GTC day, but the thing that was more important to me was the fabric, NVLink, and NVSwitch. I have long maintained that Interconnect is the most important vector of competition in the data center. In the race to exascale and beyond, it isn’t about the speed of each chip, but how fast the chips talk to each other.
This has long been a well-known problem in the micro sense, called the Von Neuman bottleneck. This is the fact that the limiter to CPU speed is the amount of memory available to be fetched and then processed. Think of it as a line that is right outside of the CPU that is the actual bottleneck within a logic chip. This same problem also applies to the data center.
Now I want you to take a bigger step back. Think about what Jensen calls the “next unit of compute” - the data center. Think of the entire data center as one big computer, with infinite CPUs, GPUs, and Memory. The bottleneck is still memory, and how fast each of these units can be fed information. This is where faster interconnects and in this particular case, NVLink and Switch come into play. NVLink and NVSwitch help expand one chip’s memory to the entire cluster at the rate of 900 GB/S.
NVLink is the interconnect fabric that is a proprietary interconnect fabric that connects GPUs and CPUs together. Importantly it is going to be compatible with CXL (NVLink) and that is opening the historically closed Nvidia ecosystem. Because this is where Nvidia is starting to create a bit of a computing platform. I think NVLink is Nvidia’s data center-wide strategy going forward.
First, it seems like NVLink is meaningfully faster than the PCIe 6 spec that is coming out this year, and yet is still compatible with CXL. Compared to Infiniband this seems more “open” as an ecosystem than before, and this is where I think Nvidia is really playing for. NVlink and NVSwitch so far seem to be the most compelling fabric I’ve seen for very large scale outs of GPU nodes, and by opening it to their products AND CXL it’s likely many of their customers will use NVLink in some manner alongside CXL.
The real part that is interesting is the addition of Grace and the DPU. Refer to this graphic below - where they are trying to say that they will peer any of their customer’s IP with their NVLink because of CXL compatibility. This is a custom yet open compute platform for the data center.

Grace is a real trojan horse. I don’t think it will be a lower full cost than the likes of Graviton or other Arm-based CPUs currently, but the Grace CPU “super chip” will conveniently have cache coherency that is unlikely offered by fabrics currently. Given a company is running a large number of Nvidia GPUs, it is likely easier than ever to add a DPU or CPU to their entire stack than ever and they will be connected faster than their current CPUs. And importantly NVLink and NVSwitch compete in what really matters, interconnect speed.
By opening up to the CXL standard but having what seems to be the fastest interconnect fabric they are essentially opening the walled garden to everyone, and theirs happens to be the fastest. CXL interoperability prevents customers from feeling lock-in, yet by super setting the speed of CXL they offer a more compelling case.
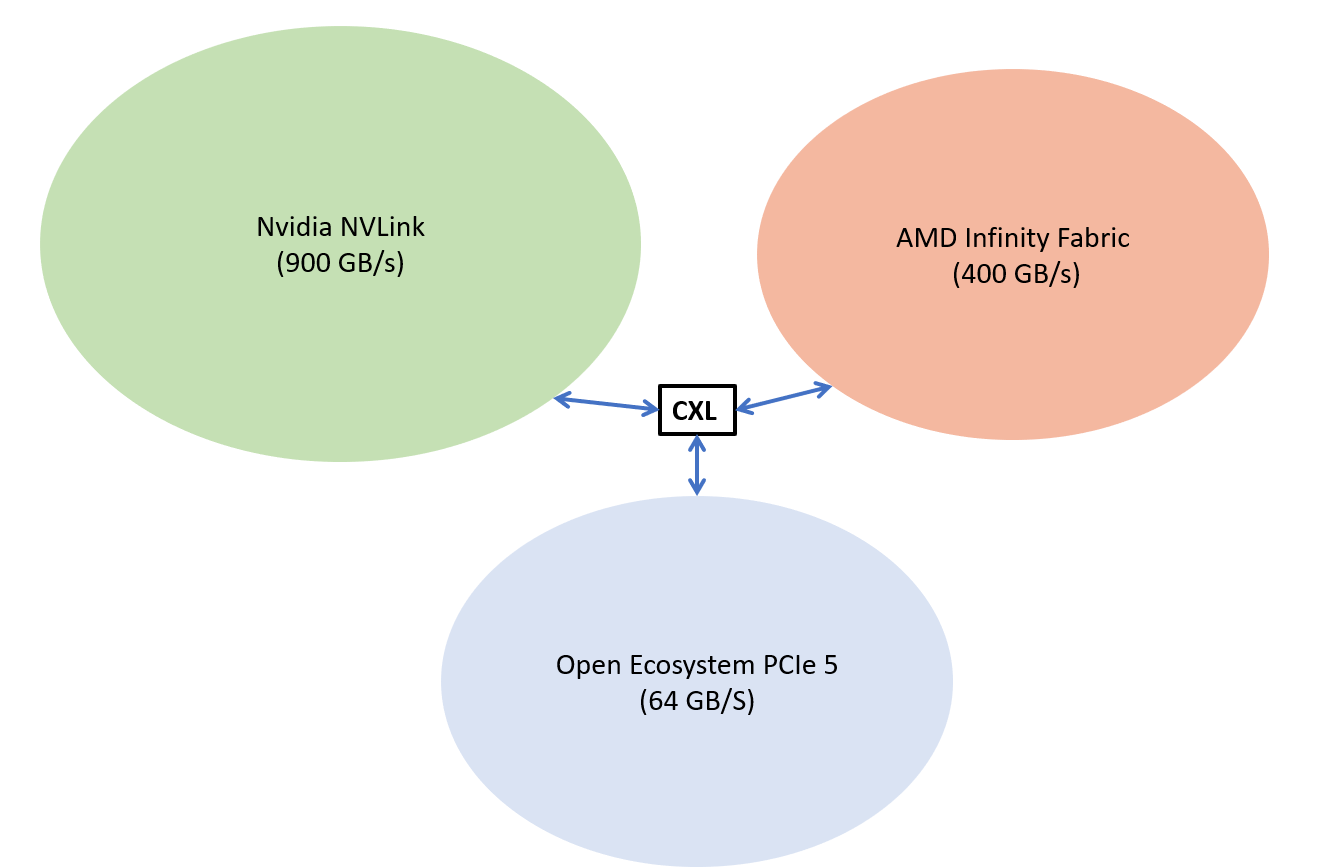
Everything else being equal the hardware should flow to the ecosystem with the fastest interconnect technology since that is the biggest bottleneck. Grace doesn’t have to beat Intel or AMD, it just has to tie them on performance and then offer the fastest and fully supported interconnect technology. Grace is close enough.
NVLink is trying to superset CXL as an ecosystem, and if they can offer products that at least match the other slower ecosystems they should win everything else being equal. Now I’m sure their customers don’t want Nvidia to have this advantage, but if they were to start to adopt the NVLink/Switch fabric into their technology stacks it would essentially be like admitting defeat. But I understand why it is compelling.
Also offering the NVLink and Switch fabric as a way to connect your custom IP is pretty attractive. And in addition, if your roadmap ever fails or has bumps, you have an attractive second source option, Nvidia’s SKU of your own custom IP. I don’t think it’s likely but if the AWS Nitro DPU started to improve less or has yield and ramping issues, they could always be the second source at Nvidia. This is all possible in a world where NVLink and Switch are the primary fabric of the data center.
Nvidia is launching a platform of computing anchored by their interconnect and GPU. By supporting CXL, Nvidia is making NVLink an opt-out, but it is also an opt-in. Lowering switching costs and letting compute flow to the fastest interconnect. Nvidia’s NVLink is a genius play in the data center wars.
Micron’s Earnings and Datacenter
Micron had a really solid print. The thing I was focused on is they sequentially added more dollars this year over last year, which was a big surprise. However, by every metric, it looks like they should decelerate revenue soon. Historically this is the end of a memory cycle, and they would have to do ~9.5billion in revenue next quarter to buck this trend.

That being said I want to dive a bit deeper into the call. I can summarize it broadly as PCs and Smartphones were less bad than expected and data center continues to be strong. This is a theme everyone should be deeply internalizing right now - the data center is the cycle. Smartphones do matter, but the data center is the driver’s seat now.
Last year, data center became the largest market for memory and storage, eclipsing the mobile market. Looking ahead, we expect data center demand growth to outpace the broader memory and storage market over the next decade, fueled by secular drivers in cloud and healthy enterprise IT investment. Memory and storage share of server BOM costs already exceeds 40%, and this number is even higher for servers optimized for AI and ML workloads. This growth is supported by new heterogenous computing architectures, the increase in data-intensive workloads, and ongoing displacement of HDDs by SSDs. In the fiscal second quarter, data center revenue grew more than 60% year-over-year, supported by robust demand across our DRAM and SSD portfolio.
Micron continued to iterate the thing that Investors are most skeptical of, that PC will be flattish for 2022. Their reasoning is that consumer is weaker but enterprise and desktops are making up for that weakness. That is the reopening and working from the office flowing back. That being said they guided for decent revenue growth, and importantly they added this interesting tidbit in their presentation.

They think they can outpace cost reductions in the industry, that’s a bold call. Their explanation however was vague, summing up to “technology” and that they invested in clean rooms already, meaning that they benefit more from adding tools and don’t have that headwind of cost of building shells.
Regardless I thought Micron was a solid print amid a world of worries in semiconductors right now. They did everything right, but given that the cycle could be turning this might not be enough. I’m not particularly bearish or bullish on the stock but thought that the continued PC flattish and smartphones not being as bad as feared is good news.
I’m pretty interested in their NAND cost reductions. I think that means that there is a possibility that NAND spending this year is really sluggish, which seems to be the biggest unknown for semicap spending this year. I am on the fence here as well.
