
Scaling Laws Meet Economics, but Adoption is still Accelerating
Economics is the primary Scaling Constraint, and despite it ChatGPT usage is hitting real scale.
Technological model scaling is not dead, but we are clearly at a critical moment when the definitions will shift. Pre-training, the original scaling law, might hit its first diminishing return. The piece SemiAnalysis used the analogy that pre-training was like the end of Dennard’s law. However, multi-core scaling led to another decade of scaling transistors. Technology progresses, just not in the same way.

In this graph, I think we may be encroaching on the early 2000s. The end of Dennard’s is almost a perfect analogy, and more so, pre-training isn’t even over; it’s just starting to see its first diminishing returns. A larger model will increase performance, but pre-training is diminishing. The improvements from GPT4 to 5 will continue, but the real issue will not be whether models can scale but the economics of whether it’s worth training a bigger model.
I think people forget that the original scaling laws paper was about orders of magnitude increases leading to only a 10-30% improvement in error rates. GPT5 might be closer to the lower bound than the upper end, but even with hardware improvements from Nvidia of, say, 5x, this is a 2-20x increase in cost, depending on how many orders of magnitude you believe in.
So, what is happening today? We are starting to see the first lines of the “Law” bow out. Remember - all technological laws, even Moore’s, are just a desire by humans to continue to improve at some constant rate.

The problem I don’t mention is that the line going up costs money. Each of those “lines” of improvement has different cost curves, and it might make sense to hop off the pre-training cost curve onto another cost curve.
Unlike most charts going up, the black line of total improvement is log-linear, so we discuss orders of magnitude cost. Even with better silicon, marginal improvements are paid in exponential dollars. How long can this last? Data will be a considerable constraint, but the more you spend on models, the better they can be. The problem is if you use this logic, you can spend the entire GDP of the world on a model, and it will be the best possible, but the economics underneath it will not make any sense. That’s evident; the problem is where the marginal return is.
Test Time Compute to the Rescue
Scaling is not “over”; it will change. This is a massive violation of the original pre-training laws, but Test Time Compute is the candidate for what’s next. At Neurips, Noam Brown called it a “GPT 2 era” level of opportunity for test time scaling.

The problem is that the actual techniques for solving this will be complicated. There are many interesting techniques, such as skipping responses, using a federation of inference models, and searching the model space. Test-time computing will create a new frontier of choices, which I think is the future.
Optimizing Frontier Curves
Think of making a better model as a frontier curve. Simplistically, more pre-training is a better model, but there’s a diminishing return at some point. You can throw Infinity Compute at the problem, and maybe it would be a perfect model, but we are talking about tens of thousands of dollars for a single inference. That probably isn’t “worth it,” but it could and should be possible.

Naively scaling out the biggest and best models probably doesn’t make sense anymore. But here’s the thing - for the longest time, AI labs have naively scaled that to the point where the silicon and hardware underneath the models could not serve this model cheap enough to have a business model. It’s like making an F1, fast, performant car, but you won’t sell many of those. You need to create various options regarding the costs that live under the curve. This is the current Meta, but we’re missing a dimension.
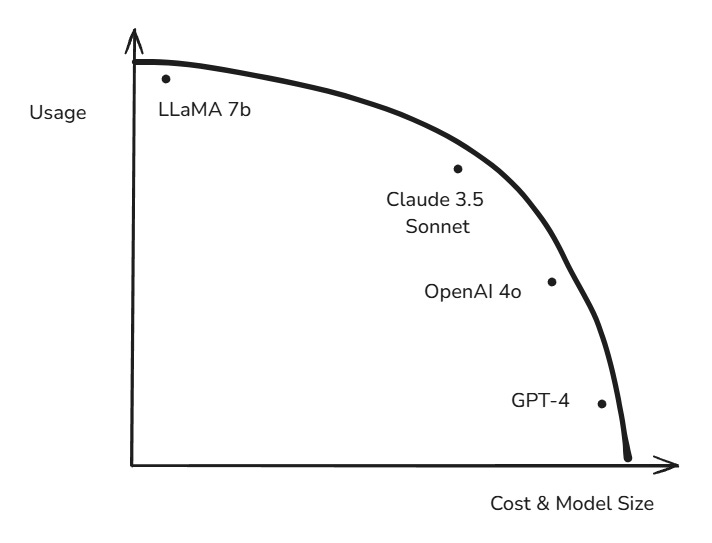
So, what’s the solution? It’s probably a smaller model. Now, pre-training is just the only option that feels simplistic. I’m drawn to the frontier curve analogy, like reducing risk and reward in finance. I won’t get into the weeds here, but there’s another axis, and it will be test-time computing.

Test-time computing will open a new Z axis. What’s more interesting is that within the optimization space, a considerable bottleneck will force AI labs to choose specific points in the curve broken by hardware requirements. This chart from SemiAnalysis’s scaling law piece best shows this. The curve has distinct kinks based on batch size, which depends on the hardware.

So now we have hardware as a real constraint. I think memory coherent space will be the critical “budget” that dictates the economics of a served model.
Memory Pool will Likely be the Budget Constraint.
In the above optimization space, you can make a vast model serving many users with large batch sizes but diminishing returns on scale. Or you can make a better-trained small model and scale that smaller model in a vast context window using test time computing. The reality is that the optimization space is going to be a bit lumpy, and the memory budget will entirely dictate it. There will be a fundamental trade-off between memory and the type of model you can serve.
I think the GB200 will massively lower the cost of model servicing. Today, OpenAI’s O1 model is constrained by the inference nodes being 8x100 SXM H100s or H200s, which have only 1.128 terabytes of memory. The next generation of GB200 NVL72 will have ~30 TB of unified memory, including the LPDDR on the CPU. That is a 30x increase in memory, which will be a massive boon for serving test-time compute-optimized instances.
It Still Takes a Lot of Compute - ROI is the Constraint
Pre-training has meaningfully slowed down. As much as I want to say it’s all okay under the hood with new methods like test-time compute, this is a bit of a narrative violation. But you can look out and see what’s next, and the reality is that good things never last forever. And Pre-Training is not “All You Need.”
The next generation of models will have tradeoffs and constraints. Maybe the 5 gigawatt cluster is canceled, but 95% of the demand is fungible. Large clusters have much better economics than smaller ones, and this relationship probably holds up to 1 gigawatt easily. Test Time Compute has hilariously larger model sizes and is computed to serve. And we aren’t even talking about the post-training needs of step-by-step RL. The market is willing to fade all data centers and think we are returning to 10-megawatt shells. We are not going back there; the data density is the most important way to scale the cost of computing down.

It couldn’t be further from that. The 5 GW cluster might be canceled, but 10 500 MW clusters are justified. It’s just a cheaper cost of computing.
Now it’s time for my favorite part - the one thing no one seems to be talking about or cares about. Adoption is still accelerating, and that part of the discourse appears empty.
