


The Internet as You Know It Is Dying
Humans are not alone on the internet anymore. That will change the Internet as you know it.
If you pay attention, the Internet has been a bit different lately. Many of the attributes and ways we once interacted with the internet is changing. I probably noticed it the most when one of my favorite websites, subredditstats.com showed me this image the other day.

Reddit’s free API is closing. But so is X (formerly Twitter), and other properties all around the internet are slowly adding limits and closing their doors. The World Wide Web is not entirely as free and open as it once was. Open APIs and ecosystems are dying, and the gatekeepers to these platforms are raising their walls and shutting their doors. I think that’s because the internet's business models are changing, shifting from collecting data to selling data.
Elsewhere, you can slowly feel the internet enshittifying everywhere. Google search results are clogged with paid results, and X breaks down frequently. Hell, it feels like our web experience, in general, has gotten worse, not better, over time. Part of this is the push for monetization, but another aspect that drives the internet's enshittification is the changing business model of the next killer application: training LLMs.
In the rush to make bigger and better models, we are not only changing how we compute and the infrastructure around that, but also the internet itself. I think this is the crucial next step of the internet, and Web 3.0 will not be the democratization of the internet, but rather just one giant training ground for what’s next. The internet as you know is dying so it can birth the next generation of AI models.
But before I go into the future, let’s dive into the past. Then, we can discuss where we are today and what I see Web 3.0 looking like. Because it frankly looks a lot less innocent than Web 2.0
The Young and Free Internet (Web 1.0)
I want to start at the beginning. Initially, I would argue that the internet our parents warned us about was free, experimental, and extremely useful if you spent enough time on it. For the price of free or almost costless, there was abundant information, community, or whatever else you were looking for springing up in every corner you could find—web blogs of ideas, forums, free internet browsers, and free email. The concept of paying for this new and novel media and information was relatively novel. An “internet job” was a rarity.
There was a lot of excitement in the earlier days of the internet. The entire world was being connected online, and the possibilities seemed endless. People created personal websites on platforms like Geocities, sharing their thoughts, experiences, and passions with a global audience. Email services like Hotmail and Yahoo! Mail allowed people to communicate instantly across borders, while instant messaging platforms like ICQ and AIM fostered real-time conversations and online communities.
The early Internet was a Wild West, with few rules and regulations. It was a playground for experimentation, and the scale was massive. Of course, there was a gold rush for this new land, and this vast new landscape led to considerable investment. That, of course, led to a boom and then a bust. But that’s the story of the internet bubble, one we won’t have time to discuss today.
But as the Internet grew and matured, a clear shift into a new era of possibilities happened. The shift was what is widely called Web 2.0 and the actual growth of Internet businesses. This is when user-generated content exploded, the interactivity of the web itself happened, and, of course, social media.
This was the land rush that eventually created the gatekeepers we have today in the big technology firms. I would call Web 2.0 the aggregation era and the beginning of the walled gardens.
Walls Come Up (Web 2.0)
Google, Facebook, YouTube, and Amazon are examples of the classic Web 2.0 companies. Each company had a different business model, but the social media companies, in particular, started with a free product and then used the aggregation of the content and power they had over the users to direct attention and sell ads against that attention. Aggregating these user bases was powerful because the marginal cost to these companies was practically zero. That is the story of Web 2.0 and is best understood through Ben Thompson’s practical Aggregation Theory framework.
During this period, the name of the game was users. Free products to create large user bases, and then slowly raising the walls around the “free garden.” The benefits of Web 2.0 were, of course, massive distribution and vast amounts of data. These set up these companies for considerable advantages in the next paradigm.
During this period, the goal was to share your content with other gardens and eventually get the user’s eyeballs on your own garden. That’s why some social media companies (TikTok) were, at multiple points, the largest advertisers on other platforms. I would argue that these market share shifts lasted well into the 2010s, and the most mature vision of the Web 2.0 era was in the late 2010s. 2019, the last year before the pandemic, was the best steady-state example of Web 2.0.
What came next was COVID, which created a demand spike that led to excess spending on the internet gardens. Eventually, the crash came from the other side of that spending spree.
But amid that sea shift from offline to online, there was another quiet change that would begin the next shift: GPT. I wrote about GPT and the writing on the wall for compute, but never thought about what that would mean for the entire internet. That brings us to today. We are hitting the maturity of the internet, and there is a need to push these mature businesses to monetize. Now, the most apparent method to monetize the scale of your data is AI training data.
Maturity and Business Models
The internet and user adoption worldwide are not in the early stages anymore. According to some estimates, 70% of the world uses the internet, and this graph shows that internet penetration is slowing down. COVID might have been the last big push to full adoption, and now we are hitting the asymptote. That forces companies to not rush for users anymore but rather rush for business models.
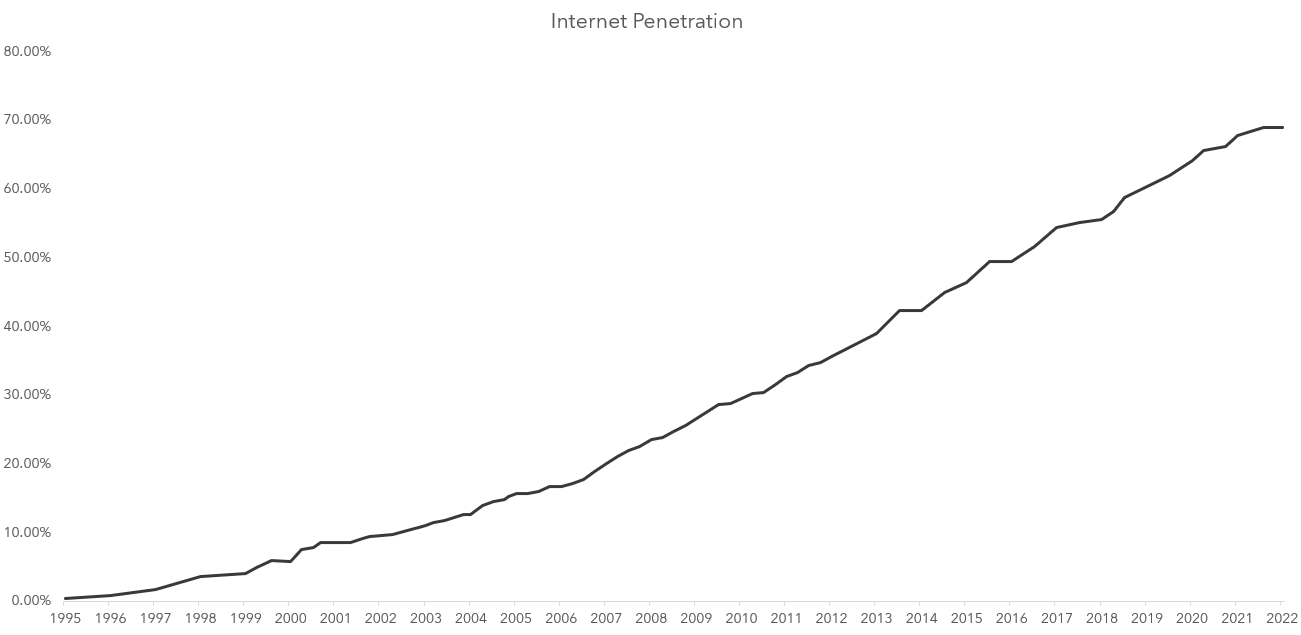
You can’t win by getting more users; all the new users have likely joined. You are fighting a relatively fixed game, not the one in which we still add tens of millions of users yearly.
The best example is Reddit, which, according to Similarweb, is among the top 20 global websites and number 10 in the United States. Reddit has about as much scale on the internet as you can ask for, yet Reddit lost massive amounts of money until recent data licensing deals for AI. If Reddit, one of the most scaled business models around, couldn’t make money from more users, more users is not a business model promise. It implies a need for maturity and monetization, and that monetization just so happens to be harvesting data for training.
Reddit is aware of this and has shifted its entire business model to selling high-quality data to train LLMs. In its IPO prospectus, Reddit booked $203 million in contract value for its data and recently licensed it to OpenAI.
In January 2024, we entered into certain data licensing arrangements with an aggregate contract value of $203.0 million and terms ranging from two to three years. We expect a minimum of $66.4 million of revenue to be recognized during the year ending December 31, 2024 and the remaining thereafter. Reddit data constantly grows and regenerates as users come and interact with their communities and each other. We believe our growing platform data will be a key element in the training of leading large language models (“LLMs”) and serve as an additional monetization channel for Reddit.
I imagine as models become larger, and the dataset becomes more valuable, renewing these data deals will be like the new sports rights. Each year the contract value should be higher, and paying for the data will be a meaningful portion of your cost of doing business in the AI economy.
Reddit I think realizes this. The prospectus of their IPO is a very AI-driven document, and you’d think that for a social media company for humans to interact with each other, they would have a different focus, but AI truly is going to be the business model going forward. It’s time to shift the mindset about the internet from gathering users, to collecting data from your vast set of users.
Finally, Reddit’s vast and unmatched archive of real, timely, and relevant human conversation on literally any topic is an invaluable dataset for a variety of purposes, including search, AI training, and research. Reddit is one of the internet’s largest corpuses of authentic and constantly updated human-generated experience. Reddit data constantly grows and regenerates as users converse. As the world becomes increasingly data-driven, we offer solutions that are human- and experience-focused. We expect our data advantage and intellectual property to continue to be a key element in the training of future LLMs.
Reddit is almost a perfect example of a Web 2.0 business model becoming a Web 3.0 model. With this mindset of capturing data from humans to train models, I think we can glimpse what’s to come. Welcome to Web 3.0.
The Cradle of AI and the Grave of Web 2.0
The core of my thesis is this: Web 3.0 will be defined by the insertion of AI into the Internet, which will massively change how we experience the Internet. That means either a desire to gather data from users or interaction from AI agents wild on the web. As AI has already passed the famous Turing test, we will increasingly be unsure if the person is a human or an AI on the other side of the text. The past assumption that you’re talking to a human on Web 2.0 will be unknowable.
Web 2.0 was often about gathering information about your viewing, purchasing, or personal habits and then using that data to pinpoint further ads for products you could buy. That has improved to almost shockingly accurate guesses or even needs. Web 3.0 is going to be not just about collecting data about you but from you. Meaning a more extensive and detailed corpus of your speech and thoughts, all to feed the eventual machine god.
Like Web 2.0, your data will be used individually in a way that is likely close to anonymous; in aggregate, our data will be used to train models. Instead of collecting information about you, it will collect information from you. This is the crucial shift. That troll making you angry and having a back-and-forth on Facebook about being wrong might be an AI bot designed to keep you engaged for further training data.
I think it’s fair to say that Web 2.0 will likely be something akin to a beautiful, idealized version of the past, and the Internet's relative freedom and usefulness will be viewed as one of the greatest and most naive periods of our technological lives. We created, frolicked, and exchanged information freely. There was no dark mirror looking back at us on the other side, and now we cannot be sure who is human.
So, let’s take a glimpse into Web 3.0. I have no idea what the future will be, but I have some strong, specific views. One is that the future Internet will be the playground of Humans and AI.
Web 3.0 and AI
One of the most beautiful parts of Web 2.0 was consuming human content—memes of other humans' experiences, extraordinary moments shared directly on camera, and viral videos of things happening worldwide. The problem is that if you have been using the internet and assume that everything is human-generated, you will probably have a bad time very soon.
We are already at the point where AI-generated text and images can pass as human-generated content without intense scrutiny. And most are not actively browsing the web to tell the difference. One of my favorite examples of this is an entire series of AI generated plastic bottle structures that seem to have genuine feedback from humans on Facebook.
There is a whole thread on Reddit about bad AI photos shared on Facebook that are passed as believable. As image models improve, this is going to get much worse. Eventually, it’ll be almost impossible to distinguish between what’s “real” on the internet and what’s generated. Clickbait articles now have powerful new engines for generated content and images. The meme that you shouldn’t believe anything you read online might come back in full force.

Viral images of the future will go from Instagram bait to beyond-realistic pictures. The assumption that everything you see will be real and not AI will be challenged in the future. In the past, “seeing it” was probably the highest bar for what was real. How will we know that the breaking news of an outbreak of war or a large environmental disaster on Twitter is even real? The answer is that in the future, we might not.
Web 3.0 will be almost an adversarial game between humans and machines. At this point, I would argue that AI is as good at creating content as humans are and at least a few orders of magnitude faster. The real valuable human eyeballs will be constantly fought for by humans and not human sources. The thirst traps will be AI, the beautiful vistas will be fake, the internet will become a simulacrum of our real world, and being able to tell the difference will be almost impossible as models improve.
It’s amusing because this sounds exactly like what the Metaverse was promised to be, but I think there was at least this belief that it would be human-created in that representation. Instead, we have created the model to generate content for us, and the infinity of generated content online will soon dwarf the real world’s ability to. I wrote about this when I wrote about the compression of reality at GTC this year.
Web 3.0 truly will be a weird place. And as our lives are all much more online than they used to be, it will likely have many knock-on consequences that are hard to fathom yet. But I can say one thing: Web 2.0 will be missed. Humor me in one last goodbye.
The Long Shadow of Web 2.0, an Obituary
I am a child of Web 2.0. The author (Doug) was extremely online as a child, and I stumbled onto FinTwit at 24 and Reddit when I was 15. I am a moderator of a subreddit. I have been deep in internet forums since I was a child and have been to many deep, dark, and weird corners of the internet. Of course, there comes some poisoning from that fact, but I could say in high confidence that everything I interacted with was made by, shared by, and read by fellow humans. In the future, that is not a surefire guess.
The internet was and is dangerous, but in a way that humanity can be hazardous. You could see very twisted or perverse things, but they were human. The best and worst of humanity, but now we are not alone on the internet. Your AI girlfriend might be fun for a young boy on the internet, but it will also be used to extract information about us. You might also not know if they are real or fake (which already is an issue).
What happens when humanity's signal is so lost in the noise of generated content? The search cost will eventually outweigh the noise; maybe we will log off. Another much more likely and realistic outcome is we are trapped in conversations with our mirror, whether it’s an LLM, artificially generated video, or photo. Why go outside if we can see the whole world in better definition, in perfect weather, and instantly from our access to the Internet? That’s a challenging competition.
Another thing I am sure of is that the internet will have a weirdly long shadow from this crucial period. The vast majority of human-generated content was created during this period. Going forward, a large amount of the data will be generated with the help of AI, meaning that the “human” base training data set will be primarily generated from this very brief moment of time.
")
I think the ironic outcome of this is that maybe, just maybe, this period in history could have a much longer shadow than anticipated. The core models and training data sets of Commoncrawl and other datasets will be the most human in this time period.
My gut is that many of the memes, slang, and patterns of this time period will have some more significant distortion effect in the future. As we create synthetic data from this data set, the models that will generate tomorrow's data learn from today's data. So goodbye, Web 2.0. You will be missed, but honestly, your data will never be forgotten.
The golden age of a human-driven internet will be missed. The next era will surely be weirder and not entirely human.
If you enjoyed this, please consider sharing this piece! I miss the open days of the ole, but maybe that’s the nostalgia of getting older.
This writes like a long internet data pitch, and I think it is. I was skeptical of the Reddit IPO, but I can see a world where feeding the data machine of LLMs makes it immensely valuable. I think if LLMs become a huge part of our economy, the companies that are the fuel them will be valuable as well. Shutterstock, Getty Images, and Reddit come to mind. Hell, Wikipedia might be worth 100s of millions in licensing data annually. Time will tell.
I largely endorse the sentiments, but it seems straightforward there will be walled gardens for humans, free for all zones, and AI only zones. Human-only zone access will require meatspace authentication, which in and of itself sounds bad and creepy but spam bots keep forcing us there. The challenge I see for any Web 2.0 platform selling their data is ensuring it remains authentically human and not just incestuous AI tokens. So they’ll be the first to figure out authentication, either through whitelisting humans, developing sentinel AIs to flag inauthentic behavior (a losing battle but possibly a government mandated and funded endeavor for top model labs), or by adding enough marginal costs that it would make AI bots there uneconomical. No matter what, it’s going to be different.
A good peace. Things will undoubtedly change as they always do. Some for the better, some for the worse. We'll adapt our understanding, expectations, and how we interact on the internet as we go along, with a lost, nostalgic generation probably left behind unable to adapt. In short, different but the same as always. It'll be alright. ;)
I grew up on web 1.0 and was very active on web 2.0. Nowadays, I use it for information and entertainment, as I find most of the rest (forums, social media...) as a giant waste of time.
We can't trust information about anything from authorities, news sources, or random people internet dwellers and it's been that way for a while. AI has nothing to do with it. We'll learn to recognize and discard that nonsense soon enough, and then create specific trusted sources of information. Adaptation is the name of the game.
I won't miss web 2.0, but the original, wild west web 1.0 will forever remain in my heart as a special time in our history. Alas, it was never meant to last. Nothing ever does.