
The Coming Wave of AI, and How Nvidia Dominates
A basic primer on LLMs, Semiconductors that power them, and Nvidia's three-headed hydra of competition
Nvidia truly shook me awake, and while I have been writing and learning about AI, I think I forgot my north star. One of the first posts I ever wrote (almost three years ago!), before Fabricated Knowledge was a paid substack1, was GPT-3 and the Writing on the Wall.2 I know so much more than I did then, but the thesis was right. Moore’s law was slowing, GPT-3 was going parabolic, and now ChatGPT and GPT-4 have created the first real application and demand.
Back then, the writing on the wall was evident, and I said at the time, the biggest winner was Nvidia.
Of course, Nvidia sponsored this. Which brings me to my first beneficiary, team green. As it stands, I believe that Nvidia is the single purest publically traded play and beneficiary. In conjunction with the GPT-3 scaling hype, the recent Ampere release which was completely focused on the data center, and the shifting narrative towards AI training, Nvidia is clearly front and center.
Crazy enough that it was entirely true, and it’s still true today! We saw the game-changing quarter, and it’s time to focus. I need to return to why I started a semiconductor-specific newsletter because I believed that would be the best way to play AI. It’s time. The wave is now crashing on the shore, and this is my attempt at a high-level AI primer.
What are LLMs?
Large Language Models and, to some extent, Stable Diffusion is sweeping the world right now. ChatGPT, the new plugins, and competitors like Google’s Bard have awoken the world to the potential of AI. LLMs are large and complicated state-of-the-art models powered by the ubiquitous transformer architecture. State-of-the-art models like GPT-4 are trained on a large corpus of data to learn the relationships in language, which can be used to answer general questions.
An LLM's goal is to input a sequence of data into it, access its vast training data and relationships it has learned between the data, and then output a correct response given what it knows and the sequence inputted.
Each model has a few key attributes: the model's size (parameters), the size of the training data (tokens), the cost to compute the training, and the performance after training. I will briefly discuss three categories: size, data, and compute.
LLMs and the data and computing that go into them are the fundamental building blocks of each model. In many ways, we can predict the performance of LLMs by the amount of computation, dataset size, and parameters. Furthermore, we know that the larger these variables, the better models will perform. This is a screenshot of the famous “Scaling Laws” paper.
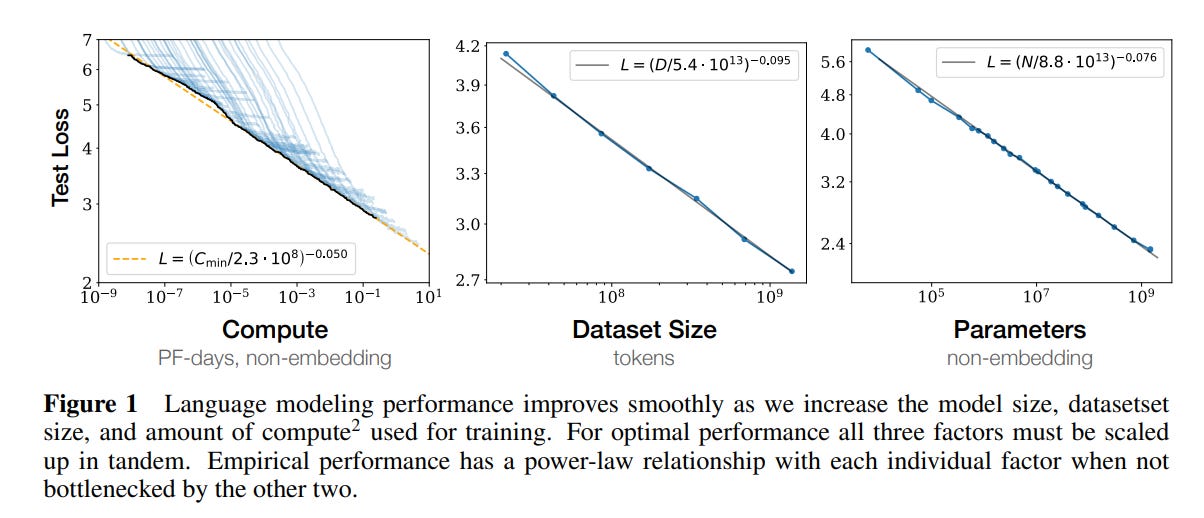
The relationship isn’t black and white, however. Papers like Chinchilla show other ways to scale to better models with different constraints, but I digress.
The important takeaway is that GPT and other LLMs will improve but likely improve from increasing data, size, and computing. Given that, something must store that data (memory) and something must train the models (compute), this is very good for the underlying infrastructure. In this case, semiconductors.
Training and Inference
I want to discuss training and inference briefly. Each step is important in creating and then using a machine learning-based model.

Training is a data and compute-intensive process. “Training” refers to teaching a model to understand the relationship between the input and the output data. The dataset is loaded in batches, fed into the model, calculates the model’s predictions versus the target, then the data is carried out, and the model’s parameters are adjusted. The model is trained many times until its parameters and performance are optimized, and it has “learned” all it can from the data. Each time the dataset is loaded into GPUs and then taken out takes a lot of bandwidth and computing. Remember GPT-4 is 1 trillion parameters which are 4 TB of model weights, with petabytes of data moving in and out of the model, calculating differences over and over.
Inference is the other side of the coin. Once a model like GPT-4 is trained, it can accept new input data and then try to predict an output using what it’s learned from training. It doesn’t know the right answer, just the answer that its parameters tell is correct.
Inference is a bit simpler but still compute-intensive. The model parameters are loaded into memory, given input data, and then the model predicts the output but does not update its parameters. It just passes you a result.
How Do Semiconductors Benefit from LLMs?
AI models like LLMs and Stable Diffusion take a lot of computing power. These models are huge. One way to think about it is that each parameter or learned trait takes up data manipulated and used massively. GPT-4’s 1 trillion parameters are 4 terabytes of data being loaded into memory, passed information, and computed. That’s a non-trivial amount of computing for inference, and the cost of training can spiral into the 100s of millions of dollars, given the number of times the model parameters are tweaked.
I’m trying to say this is a lot of computing, and the semiconductors underlying LLMs are a huge constraint and strategically important for model performance. I will walk everyone through the demand dynamics and then give an example of a typical AI workload. Nvidia’s products are essentially the vast majority of training and a meaningful percentage of inference today. I’ll discuss why Nvidia is in a second. First, let’s talk about the ways that AI influences semiconductor demand.
The Compute Problem
I cannot stress this enough. AI-enabled workloads like training and inferences are more hardware intensive and costly than before. Let’s compare AI workloads to “legacy” workloads, like traditional SaaS or social media operations. SemiAnalysis, run by the GOAT of semiconductor industry analysts, Dylan Patel3, estimates ChatGPT costs .02 cents a query.
Training costs are not that high, and they continue to fall. The utility of the largest models is undeniable. Given inference costs for GPT-4 are so cheap (0.02 cents per 1,000 tokens inclusive of OpenAI and Azure’s margin stacked on top), there’s very little reason to stick with small models. As such all major tech companies are racing to build clusters larger than this for training, and in most cases multiple for teams to experiment with new model architectures.
That is roughly a CPU hour in terms of cost. Each query for ChatGPT costs as much to run a CPU in a data center for an hour, which can be consumed in seconds.
And a reminder that the GPUs powering OpenAI are specialized for the task. The amount of computing it would take to host a website for an hour is being used in a single query, and the ChatGPT model and LLMs are often multiple queries over and over. In a future where AI is added into many more aspects of our lives, you could likely run up a bill that would cost orders of magnitude higher than most websites or SaaS applications in just an hour on ChatGPT. This is a step function higher in demand, and as the world becomes more AI-intensive, hardware demands will soar.
We are talking about inference; training is the real beast of a computing problem. Training these extremely large models can take 10s if not 100s of millions of dollars. Why are these models so intensive for compute costs? It has everything to do with what I said about the data loading, parameter processing, and output process mentioned above. In addition, the computation required for Just running or using the AI instance once accesses more data than your workstation can hold. These models are larger than any one computer, and that’s where stringing multiple computers together into a larger system becomes important. Let’s talk about the interconnect problem.
The Interconnect Problem
I mentioned above the amount of data and size of the models being trained and inferenced, and I want to spend a second talking about one of the key constraints of AI training and inference, which is interconnect.
Let’s talk very briefly about the Von Neuman bottleneck fundamental to computers. The perfect computer has the logic, the memory (data), are all in sync, and memory is perfectly available to memory. But there’s a bit of a catch; in the current technology, the logic is much faster than the memory availability to compute it. Some techniques are used, such as caching and parralization, that are used to improve the availability of memory to compute. But this problem hits a brick wall when it comes to AI, as the amount of data being processed is so much higher than the past.
Let’s take training, each time the model is trained, the parameters have to be held in memory near the GPU or accelerator, and there isn’t a single rack in the world capable of holding half a petabyte4 in it’s memory, so the problem has to be split into smaller units and parallelized across other computers. This would be like cutting the larger problem into larger slices like a pizza, and having each slice cooked separately then put back together into a larger pizza. There isn’t an oven big enough to cook 1 whole pizza.
In some aspects, GPUs were purpose-built for this kind of parallel problem, but even the large memory and number of cores cannot train the largest models today. So how fast all the “ovens” in this analogy work together is a huge limit on the effective speed of the overall machine. The pizza isn’t finished until each slice is, so how fast all the parts work together is a huge constraint and limit on the entire system. This is the interconnect problem.
Nvidia has probably the best and most parallel process today. Not only are all the GPUs connected in a single rack, but each of the racks is connected to the other with NVLink, making each GPU connected in the rack and the racks connected at a very fast speed. This interconnect speed is one of the biggest bottlenecks, and currently today, the DRAM bandwidth in particular, is among the biggest problems for how to scale AI training in the future.

How LLMs are Trained and Inferenced Today
Giving tangible examples of how models are trained is likely one of the most helpful ways to “get” what Nvidia is doing. Let’s talk about Nvidia’s products for both training and inference and look at a real-world training and inference solution.
Training
Nvidia’s DGX is likely the most popular model for training today. They recently announced an upgrade to their new GPU, the H100, but the DGX is the gold standard for training.

Each server rack has 8 Nvidia H100 GPUs connected to every other GPU, with 4 NVSwitches connecting the GPUs and 2 Intel CPUs. Each rack costs upwards of 500k and can train meaningfully large models. However, extremely large models take multiple racks to train a single model. For example, GPT-4 was trained on over 16,000 A100 GPUs, according to SemiAnalysis.
The actual mechanics of training is similar to what I discussed above. The data is moved from static memory (NAND) into working memory (DRAM), the parameters are loaded into the GPUs, and the model is fed data until the answers converge. Then the model is taken out of working memory and evaluated. As you can tell, GPUs do most of the heavy lifting, but data is being moved back and forth at massive speeds.
In reality, training models like GPT-4 take more than a single 500k server blade, but rather thousands of blades working together to train the model in parallel. This is the concept behind the SuperPod, which aims to scale many DGX blades into a single larger GPU cluster. The problem of the extremely large model is then split into smaller pieces and worked on in parallel as if the entire data center was one giant computer. This is the concept behind the phrase “Datacenter as the New Unit of Compute” that Jensen Huang likes to say so often.

As models improve by becoming larger, this trend should continue. We know models will improve if they were larger, but currently, we are constrained by hardware. When the new H100 comes out, newer and larger models can be scaled.
Inference
Inference is a bit different. Remember the inference and training commentary above, where the parameters constantly changed? That doesn’t apply. Now data (input) data is brought into the machine, the parameters predict the output data, and the data leaves. This is not quite as intensive as training, but still, very memory and compute-heavy and has a much larger workload compared to CPUs today.
The inference end state has not been decided yet. While Nvidia dominants the training market and has a great competitive product for inference (ChatGPT is inferenced on Nvidia GPUs), the market for inference seems a bit more open than training, where Nvidia’s moat is the strongest.
Here’s a mediocre chart from Mckinsey, which says most of the inference today is done on CPUs, and tomorrow it will be done on ASICs. So far, this prediction (as well as the training prediction) seems to be completely bunk, as Nvidia dominates. There is a lot of possible space for inference entrants, given that the compute flow seems more flexible than training.

Anyways speaking of domination, I want to talk about Nvidia itself. I think something is interesting here: how they compete. Nvidia has three vectors of competition, and I call it the three-headed hydra.
Nvidia as King Maker and the Three-Headed Hydra
This didn’t intend to become an Nvidia primer. The reality is that it is because of how dominant Nvidia is in this entire ecosystem. I will talk about what I see as their concentric levels of competitive advantage because Nvidia has something very special here. When you ask Jensen his thoughts on competition, I think he is unwilling to compete where he thinks it is commoditized or Nvidia cannot dominate. Nvidia is the clear leader in each of the three big places they service but offers the whole solution as a product.

The result is that Nvidia has taken meaningful parts of the AI value chain that many larger players cannot replicate meaningfully or quickly. To beat Nvidia is like attacking a many-headed hydra. You must cut off all three heads at once to have a chance, and meanwhile, each of the heads is already the leader of their respective fields and is working hard to improve and widen its moats.
We saw this after the wave of AI hardware startups failed. They all offered a type of hardware that was as good or slightly better than a GPU but failed to offer software to support the hardware and solutions that scaled up to solve problems. Nvidia did all of this, and fended off a single thrust. This is why their strategy is a three headed hydra, you must defeat their moats in networking and systems, Accelerator hardware, and Software all at once.

Meanwhile, access to their platform currently feels quite like kingmaking right now. OpenAI, Microsoft, and Nvidia are clearly in the lead. Google and Amazon, to a lesser extent, have tried to create their ecosystems. While Google is closest to the full vision, Nvidia is still clearly in the lead and offers the most compelling full-system solution. Meanwhile, Amazon is struggling to get a model, has some amount of computing, and does not have enough software support. I think SemiAnalysis’s prescient post about Amazon losing the future of AI cannot be more true.
Google has the broadest portfolio, but Nvidia is the leader, and its three-headed hydra is arming the entire ecosystem that isn’t Google. And today, it’s clear who the winners are using; it’s Nvidia. Nvidia is reinvesting and winning, and to enter their space means you have to enter the hardware, the software, and the system-level business. Best not to miss if you come at the king because few entrants rarely survive.
The Semiconductor Stocks
Now I want to talk briefly about the stocks. I have even more updated ideas than my last post on Nvidia, particularly on margins. I also want to discuss a heat check, some other companies I missed, and what I think will happen. That’s all behind the paywall.
