
CXL: Protocol for Heterogenous Datacenters
First, I want to thank Tegus for sponsoring this post. The newsletter won’t change, but Tegus is allowing me to expand my resources and use their expert network to help me make a better product. Most of the core work was done using Tegus calls for this piece. All the transcripts will be linked in the postscript.
I have had many offers to sponsor the newsletter before, but I only felt comfortable promoting companies I would use myself. Tegus is one of the few companies that I really could stand behind. If you’re an analyst doing work, expert networks like Tegus can be a valuable part of your process. It helped speed up my research process for CXL. Anyways onto CXL.
And let’s not forget if you want to listen to a podcast - Dylan at Semianalysis and I did a recent podcast about CXL, BS-PDN, and other topics. Pretty topical with this post.
CXL will be one of the most crucial regime shifts in the data center. So before we talk about what CXL is, let’s talk about the core problem it solves. And that goes back to a recurring obsession - the interconnect problem.
The Interconnect Problem
The first paid post on Fabricated Knowledge was about interconnect in the data center. Now more than ever, interconnect is becoming one of the most critical enablers in this post-Moore’s law era. Performance is now partially determined by the ways to improve interconnection between chips, particularly memory.
Advanced packaging is a solution to this core problem at the micro-level, and speeding up interconnection is one of the ways we’ve managed to speed up chips as of late. Improving interconnection is so important because of a fundamental bottleneck for computers dating back to Von Neuman. Most call it the Von Neuman bottleneck.
The bottleneck is simple. In the Von Neumann model of compute1, the standard structure of computers today, a computer is fed information from memory, processes it, and puts the solution back into memory. The problem is that fetching data from memory to the CPU has always been slower and thus a bottleneck. As processors have become faster, memory rates have not. Below is a graph of the memory and processor gap.

Many recent architecture improvements for mainstream CPUs are focused on alleviating this bottleneck as chip designers stack memory on the logic die, bringing the memory closer to the processor, thus closer, faster, and easier to reach. Think HBM in most accelerators or CPUs today.
That solution doesn’t quite work in a data center the same way. While the data center's memory is getting faster and larger, the processors are still getting much quicker. As a result, the interconnection between racks in a datacenter is a massive bottleneck in machine learning applications.
But there is a sea change on the horizon, and that will be enabled by CXL and other company-specific interconnect fabrics built on top of that. But before we talk about CXL, I want to take a step back and talk about why the memory bottleneck at the micro and macro level is effectively the same problem. This helps give a bit more confidence in the CXL thesis and gives you an idea of the order of magnitude speed-ups available.
Let’s first look at the micro. The recent changes that chipmakers on a micro-level (AMD, NVDA, INTC) have taken are moving memory closer to logic and accelerators. This simple graphic shows that instead of memory connected via a PCB, it’s brought in the package and thus faster and more available to the CPU and Accelerator. Below is an example of moving memory on-chip for better performance.

As we’ve seen in chips like the Apple M1, this massively improves performance. But the problem is that moving memory closer to the chip only solves that problem on a single unit basis. Still, in the datacenter the most significant and most complex issues are solved on multiple chips scaled to the entire datacenter (unless you’re Cerebras). In particular, Machine Learning models are scaling faster than chips can manage, so you’re breaking the problem into smaller solutions across multiple racks.
That bottleneck of moving the data between racks is still the biggest hurdle. The memory is stranded in each rack and can’t communicate to solve the problem well. Before a machine learning node can solve the entire solution, memory waits for partial answers to other issues before it can move the forward state of the whole model. Think of it like a post office, where letters are coming in asynchronously, often days after new information has made the letter containing the original information obsolete. (Thanks, Dylan - I stole this from you).
But if you think about it, the datacenter is effectively one giant unit of compute in itself. And if we start to break memory into larger pieces next to compute, we can start to abstract the problem to higher levels with more elastic pools of compute, memory, and acceleration underneath it. So, for example, if we were to add larger pools of elastic memory (DRAM, to be precise) to large pools of CPUs (we have that today), we could solve the interconnect problem at the datacenter level. This would create a synchronous pool of memory that is always on the same page next to the CPU, not partitioned into hundreds of pieces of stranded and out-of-sync memory.
The implications of this are huge. I think the best way to think about this is the Apple M1 as a model of what heterogeneous compute improvement can offer at the micro-level. The datacenter is effectively one giant Mandelbrot fractal of the same problem on a larger scale. The same progress the Apple M1 chip has on the microscale would be available for an entire datacenter! The cost and performance improvements would be equivalent to a generation of performance scaling, most likely! And it’s all the same problem - interconnect.

So the trend of advanced packaging is massively speeding up computers on the chip and package level, which is the interconnect problem at the macro-level for datacenters. Jensen Huang loves to say, “the datacenter is the new unit of compute,” and fast and coherent interconnect like CXL will be that advanced packaging like innovation at the datacenter. So the datacenter is the next big computer, and there is an interconnect problem there - if you’re following my logic, this is an essential and logical innovation.
Let’s review a simple simplistic scheme of a datacenter rack below and compare it to a “CXL” enabled pooled server. The goal of CXL is to start to specialize racks of compute so they can do only 1 task exceptionally well, and instead of a large pool of generalists connected, each rack is a specialist at their direct jobs. This is advanced packaging yet again but blown up to the datacenter scale! CXL might be seen as a 2.5D interposer in the example below.
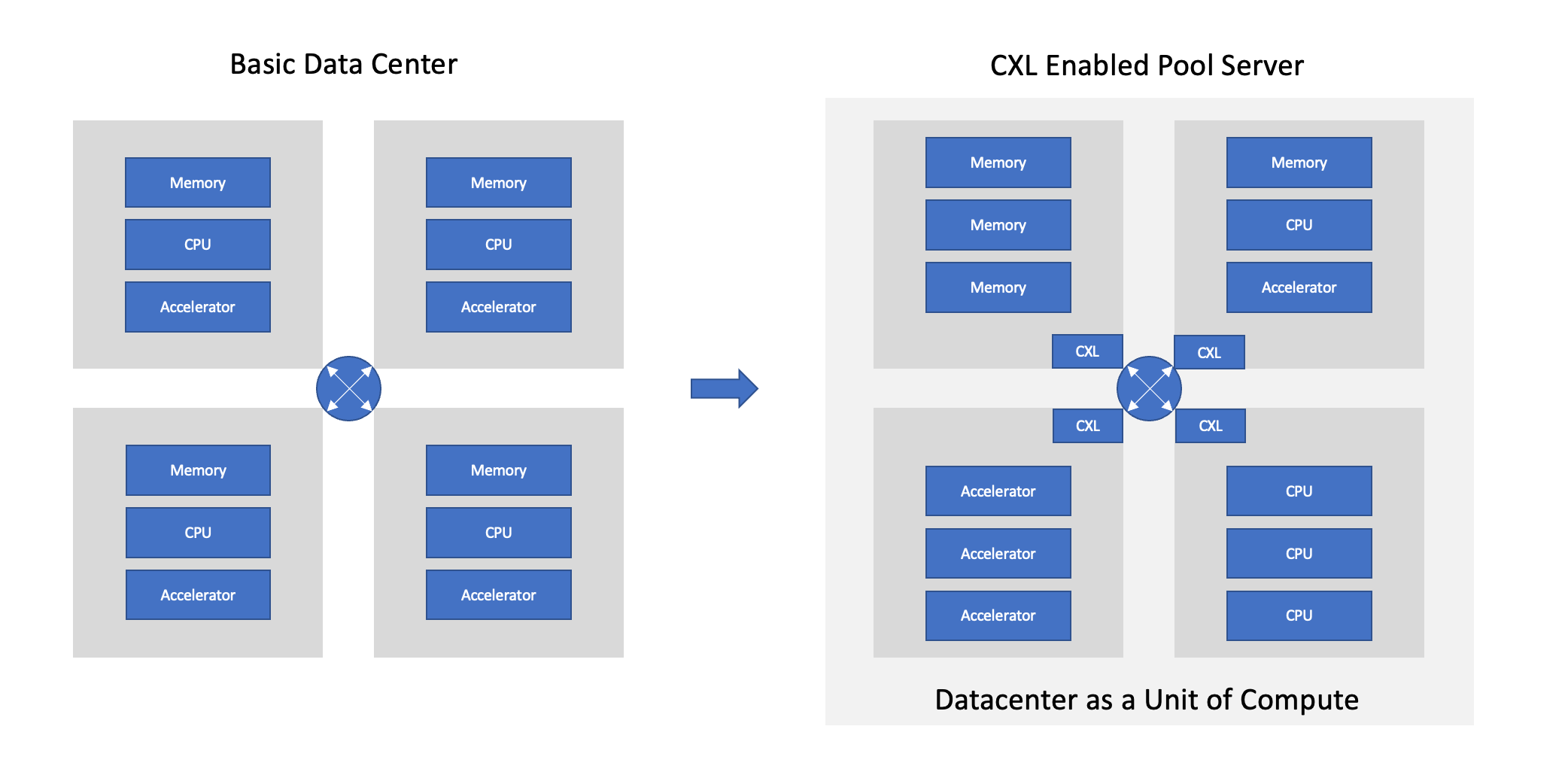
And applying what we know about Advanced Packaging becoming the de-facto way we scale compute going forward, the same solution will apply to the datacenter. How fast and coherent we scale datacenter interconnect is the problem that needs to be addressed. Making the large computer more specialized and having each rack specialize and importantly offer unlimited amounts of connected memory to accelerators is going to be one of the fastest enablers of large ML models. This will be the most critical vector of differentiation for datacenters in the future.
My simple block diagram above shows how CXL will work; there will be a small CXL controller that will bridge each of the servers. By adding a little intelligence into the CXL protocol, the accelerator-only unit can access the memory-only server rack, which effectively is a massive increase of memory for a server rack. CXL importantly maintains cache coherency, meaning that every computer in the rack is on the same page about what is happening simultaneously. It abstracts the computer to a sizeable multi-rack series.
The real magic and eventual end goal is that CXL can enable plug-and-play additions of datacenter memory to logic and accelerators, and you can add as much as is needed to fit the need. GPUs today are very limited by memory, for example, and this would help scale larger models. These implications are enormous in the most critical growth market of semiconductors; AI. Given the absolute size of models is growing at parabolic rates, the memory portion of the equation is the most challenging part to solve, and CXL attaching specialized memory to pools of computing is how we scale.

CXL will offer one of the best tools to solve the large model problem aside from sparsification. On top of that, better tools for each job will improve the products that datacenters can offer and even create new revenue opportunities in the future. The world will be blown open by the architectural opportunities CXL has to offer.
So let’s talk about precisely what CXL is, and I want to bring into the picture several different types of interconnect that each will have an important part to play.
What is CXL (and PCIe 5.0)
CXL is a protocol to connect chips. Importantly CXL will have coherency and a way for a CPU or Accelerator to communicate over fabric to talk to memory outside of its server rack. By enabling this, you can create pools of computing, acceleration, and memory, and it will all work in a large parallel array. That’s the dream, at least.
We are a bit away from that dream, but we are starting to begin the process of a few key technologies and enablers of the most likely future data center topology. The critical part about CXL adoption is the 2.0 spec is effectively paired with the PCIe 5.0 spec, and given we are just about to start rolling out PCIe 5.0 to the data center. This is the beginning of the CXL adoption curve.
CXL comes in three different flavors; CXL.io, CXL.cache, and CXL.memory. CXL.io is effectively PCIe 5.0, CXL.cache is focused on accelerators being able to access pooled memory, and CXL.memory is focused on offering pooled memory configurations.
Within the CXL ecosystem, there are three types of devices: type 1, type 2, and type 3.

The first device is a SmartNIC that lacks local memory but can leverage attached memory to the network. The second device is an accelerator such as an ASIC, FPGA, or GPU with local memory and can access memory outside of the local memory. And lastly, the type 3 device, which will be one of the more exciting configurations, will be pooled buffers of DRAM that can complement the types mentioned above of devices. For a more in-depth explainer, refer to this great primer Rambus wrote.
So to take a step back, CXL is a protocol like TCI/IP or other famous networking protocols. But it is inevitably linked in the short term to the adoption of PCIe 5.0, which is closer to a technical spec than a protocol. PCIe is often best understood as a physical fabric that connects the CPU and accelerator.

But PCIe 5.0, the technical spec, will enable this critical protocol to be used on top of it. So I hope you’re catching the difference between protocol and fabric here because it will pop up again when we talk about the longer-term future of CXL.
Anyways know that at this moment, the new technical spec of PCIe 5.0 is beginning to be shipped in server-grade chips, which will start the adoption of CXL. CXL is a multi-pronged protocol with multiple layers and devices. So let’s talk about what that can exactly enable.
CXL Enables a Heterogeneous Datacenter
I keep using the M1 as an example of the speed-ups available to whoever indeed pursues the CXL-enabled strategy first and foremost. It’s a similar expression using the mandelbrot analogy, and whoever pursues it first will have a real cost advantage. This is why I think most companies will be forced to pursue adoption.
But I want to talk specifically about products that can be offered. The foremost is offering more flavors of compute instances at the cloud providers. Below is an example of a few EC2 instances, but if you notice, there’s a pretty linear relationship between vCPUs and memory. This could be changed for smaller or heavier memory instances and create an uplift for revenue there. Additionally, this would lead to higher utilization and better economics for the data center.
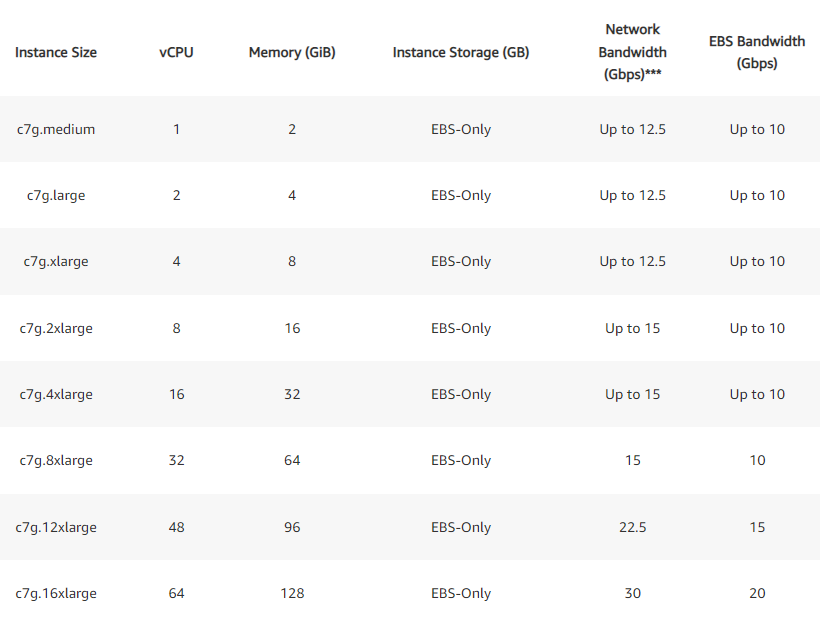
But going beyond the basic first-level instance of what a hyperscaler could provide with CXL enabled datacenter, the more compelling examples are memory redundancy and better scaling across datacenters. An example given to me was that if a server crashes during a transaction, it could likely be resumed by another server because the transaction ID would remain in memory.
Another option is high in-memory requirements for location-based services like maps or databases. Instantaneous recovery of failure of racks given pooled memory elastic and distribution perspective. There are a lot of ways this will change the game.
Memory will become tiered, similar to how memory is tiered for storage, with near-term and long-term storage options. Creating redundancy and layers of memory would help the whole datacenter act as a better computer, akin to adding layers of SRAM to the CPUs and GPUs that are the engine of the datacenter.
In the long term, the hardware strategy will probably lead to some competitive advantage as one company will be able to sell effectively a specialized compute instance optimized for a solution that another couldn’t without CXL. The net effect would be akin to the customized hardware stack at Youtube, a series of accelerators and memory custom-built for the task. I believe CXL could help companies leapfrog previous generations’ custom stacks like Youtube or, importantly, enable future solutions for complex problems to solve at scale.
How does this Change the Current Data Center?
I believe that CXL will be a huge business case change for the datacenter. Initially, almost everything related to CXL should explode in terms of dollar content. This includes DPUs as CXL will enable the future network-centric datacenter.
But the place where I’m curious about memory’s role in the data center. In the near term, I believe that hyperscalers will initially focus on creating more revenue from the new forms of memory offered by CXL, while in the longer term, they might be able to optimize the DRAM further. So what I’m saying here is that in the short run, DRAM spending will go up, but in the long run, CXL gives one of the most effective ways to manage the rising costs of DRAM within the datacenter.

This relationship that Micron loves to mention may eventually break down in the out years with pooled CXL running at higher utilization than today’s stranded datacenter memory.
Another interesting perspective is that CPUs, which have been losing relevancy, should roll into just one of the many tool pieces of the datacenter. While they will always have a crucial role, the days of the datacenter being a collection of CPUs is over. CXL will enable the best need for every tool to come forward as memory is distributed across the datacenter to the correct accelerator or network piece.
What about Ethernet?
Something unspoken here is what the hell is going to happen to ethernet? Ethernet today is the workhorse of datacenters because of the power and simplicity of fiber optics. I’m still quite a bull for top-of-rack ethernet (hello Inphi/Marvell), but I believe that CXL adoption will encourage PCIe connection within the rack.
I think short-term PCIe adoption will cannibalize 50G ethernet ports, but longer-term, I think that PCIe the fabric is toast. The dream is silicon photonics and CXL combined, and PCIe the fabric is well positioned given its close relation to CXL. I think that PCIe will eventually be superseded by a photonics-based fabric technology, but the protocol will be alive and well. The problem for investors or anyone watching is this is likely on a 10-year time frame.
So in the short term, this could be bad for commodity-like ethernet if it pushes adoption of rack level to interconnect using PCIe, but in the very long time, I think it’s PCIe that’s genuinely at risk. Of course, PCIe could start to adopt more SiPho-like aspects and live, but the jury is still out.
Okay, what about UCIE? (What is UCIe)
Everything I’ve described is how data centers work from a high-level topology. However, CXL will also be used at a much smaller level - particularly in how chips connect on a chip-to-chip basis. This emerging standard is called UCIe. UCIe stands for “Universal Chiplet Interconnect Express” and is a super-set of features on PCIe and CXL. The goal and dream of UCIe are so that multiple vendors of chiplets can be integrated into a single chip.
CXL is related to UCIe, but UCIe will be more focused on the micro-level problem of creating chips with multiple vendors added to a single package. It’s partially related to CXL because it will use CXL, but now the protocol will govern the smallest interactions (chip to chip) all the way to rack interconnection. CXL is around to stay and will be a massive enabler of both micro and macro level interconnect. UCIe is mainly focused on the micro-level.
One of the problems with making a cross-company chiplet design is that protocols are not standardized to cohesively help the chip talk to other parts of the chip. UCIe aims to solve this. UCIe will be a standard to enable heterogeneous computing on a package level from different vendors. This would make it possible for a GPU from Nvidia and a CPU from AMD to be packaged into one seamless chip.

UCIe is going to focus on two parts of the problem, at a package level integration and off-package connectivity using UCIe that will support CXL and PCIe. The spec is extremely basic and is in the 1.0 phase, but it likely will seem like the chosen winner to a more connected chiplet-enabled universe in the future.
What are Infinity Fabric and NVLink?
Something unspoken here is that almost every company will be trying to sell their proprietary fabric on top of CXL, hoping that their product will be adopted and thus a standard. The reality is, who knows what will be adopted, but at the very least, I feel pretty bullish on CXL as a concept.
I wrote a bit about NVLink here - but this is just a faster and more feature-heavy version of the open-source CXL and PCIe standards. Hyperscalers will likely support open standards to keep costs low, while Nvidia and AMD are pushing forward with company-specific fabrics. Who wins is to be determined.
Conclusion
CXL is going to be adopted in the near term, with PCIe 5.0 finally rolling out. However, I think it’s time for everyone to pay attention because this is the next big thing at the datacenter level. While CXL has been on the horizon for a long time, PCIe 5.0 is the catalyst for real products to hit the data center and for the inflection to begin. For context, I believe that 2023 is year 0 of this crucial inflection, which should continue for the next decade. No one knows how big this market could be - but this hilarious TAM graph by Micron is probably correct.

It’s tough to know who will win. Categorically I think Marvell has one of the more intelligent bets on the space. I also think that AMD, if they drive the Pensando and custom IP playbook ahead, could benefit from the whole space, but that is dependent on products that don’t exist yet. Last but not least, I have my favorite straightforward bet called Rambus. I still think it’s exciting but acknowledge the risk associated with said reward. Marvell is likely my “safest” beneficiary.
Regardless you have to be paying attention to this if you’re interested in semiconductors. The stakes couldn’t be higher - how CXL is adopted will be a significant source of incremental revenue or loss of relevance for many companies. And on top of that, the CXL opportunity is likely one of the largest incremental dollar markets in the semiconductor industry. And we are starting inning one in 2023. Time to pay attention to this space.
If you made it this far please consider subscribing to my Substack. Free or paid - both would help tremendously!
Sharing is also helpful to me! I believe that CXL is an important inflection that needs to be heard. Consider sharing with others to get the word out!
Sources and Links
In particular, I want to thank Tegus. This couldn’t have been possible without Tegus - and the three transcripts I used heavily are below.
Former Senior Design Verification Engineer at Marvell Technology Group
Former Senior Member Of Technical Staff at Rambus
Former Principal Cloud Architect at Amazon Web Services (link pending)
Additionally, this was a great video worth watching
Basic Primer on CXL memory
https://www.nextplatform.com/2021/09/07/the-cxl-roadmap-opens-up-the-memory-hierarchy/
CXL finally became the winning strategy post-Gen Z absorption
https://www.nextplatform.com/2021/11/23/finally-a-coherent-interconnect-strategy-cxl-absorbs-gen-z/
The CXL Technical Specs (Arcane reading)
https://composter.com.ua/documents/CXL_Compute_Express_Link_Specification.pdf
An excellent simple primer with more technical depth than I went into today.
https://www.rambus.com/blogs/compute-express-link/
It’s not the Von Neumann structure but rather the modified Harvard structure. For this piece, they are close enough to have the Von Neuman bottleneck still.